Cómo instalar y configurar Apache Spark en Ubuntu/Debian
Apache Spark es un marco computacional distribuido de código abierto creado para proporcionar resultados computacionales más rápidos. Es un motor computacional en memoria, lo que significa que los datos se procesarán en la memoria.
Spark admite varias API para transmisión, procesamiento de gráficos, SQL y MLLib. También es compatible con Java, Python, Scala y R como lenguajes preferidos. Spark se instala principalmente en clústeres de Hadoop, pero también puedes instalar y configurar Spark en modo independiente.
En este artículo, veremos cómo instalar Apache Spark en distribuciones basadas en Debian y Ubuntu.
Instalar Java y Scala en Ubuntu
Para instalar Apache Spark en Ubuntu, necesita tener Java y Scala instalados en su máquina. La mayoría de las distribuciones modernas vienen con Java instalado de forma predeterminada y puedes verificarlo usando el siguiente comando.
java -version

Si no hay resultados, puede instalar Java usando nuestro artículo sobre cómo instalar Java en Ubuntu o simplemente ejecutar los siguientes comandos para instalar Java en Ubuntu y distribuciones basadas en Debian.
sudo apt update
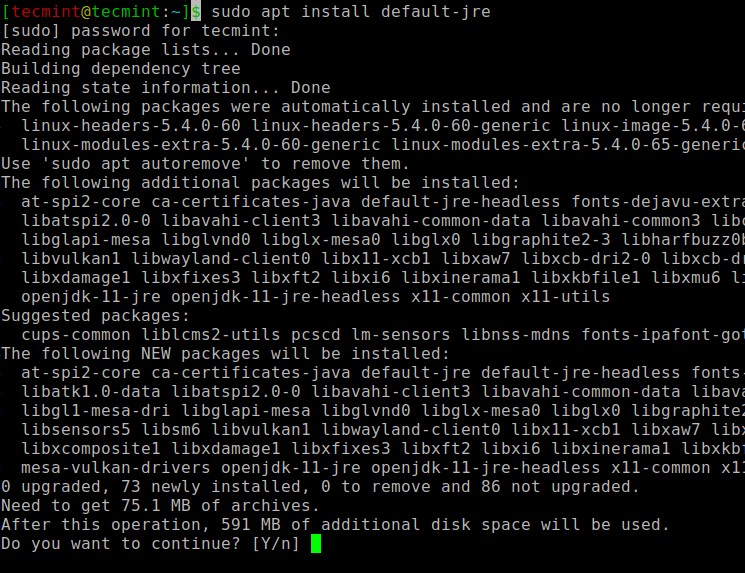
sudo apt install default-jre
java -version
A continuación, puede instalar Scala desde el repositorio de apt ejecutando los siguientes comandos para buscar scala e instalarlo.
sudo apt search scala ⇒ Search for the package
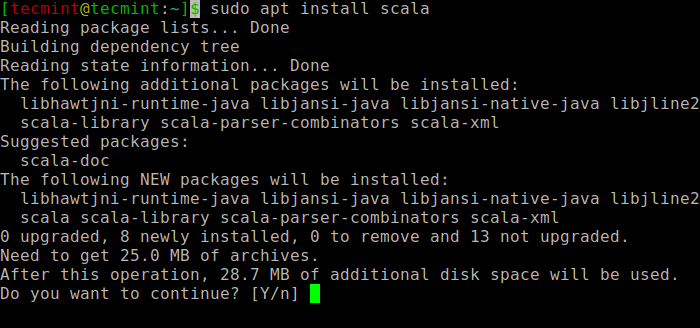
sudo apt install scala ⇒ Install the package
Para verificar la instalación de Scala, ejecute el siguiente comando.
scala -version
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Instalar Apache Spark en Ubuntu
Ahora vaya a la página de descarga oficial de Apache Spark y obtenga la última versión (es decir, 3.1.1) al momento de escribir este artículo. Alternativamente, puede usar el comando wget para descargar el archivo directamente en la terminal.
wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Ahora abra su terminal y cambie a donde está ubicado su archivo descargado y ejecute el siguiente comando para extraer el archivo tar de Apache Spark.
tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz
Finalmente, mueva el directorio Spark extraído al directorio /opt.
sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark
Configurar variables ambientales para Spark
Ahora tienes que establecer algunas variables ambientales en tu archivo .profile antes de iniciar Spark.
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
Para asegurarse de que estas nuevas variables de entorno sean accesibles dentro del shell y estén disponibles para Apache Spark, también es obligatorio ejecutar el siguiente comando para que los cambios recientes entren en vigor.
source ~/.profile
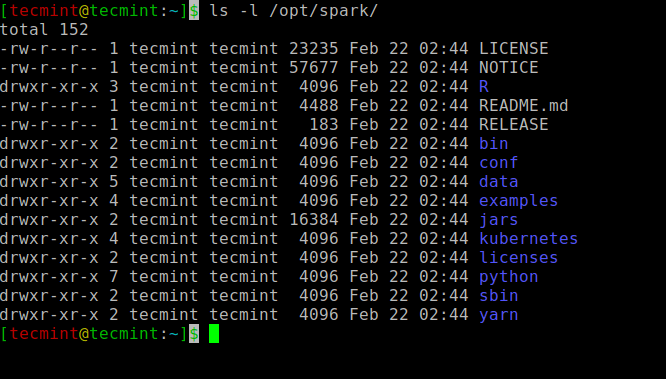
Todos los archivos binarios relacionados con Spark para iniciar y detener los servicios se encuentran en la carpeta sbin.
ls -l /opt/spark
Inicie Apache Spark en Ubuntu
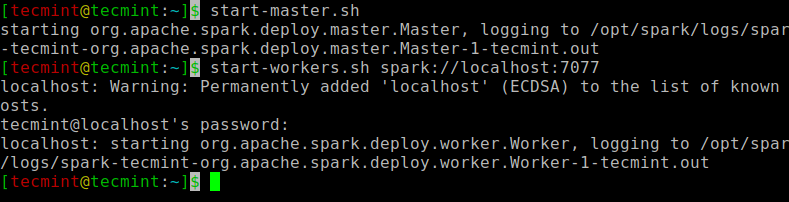
Ejecute el siguiente comando para iniciar el servicio maestro y el servicio esclavo Spark.
start-master.sh
start-workers.sh spark://localhost:7077
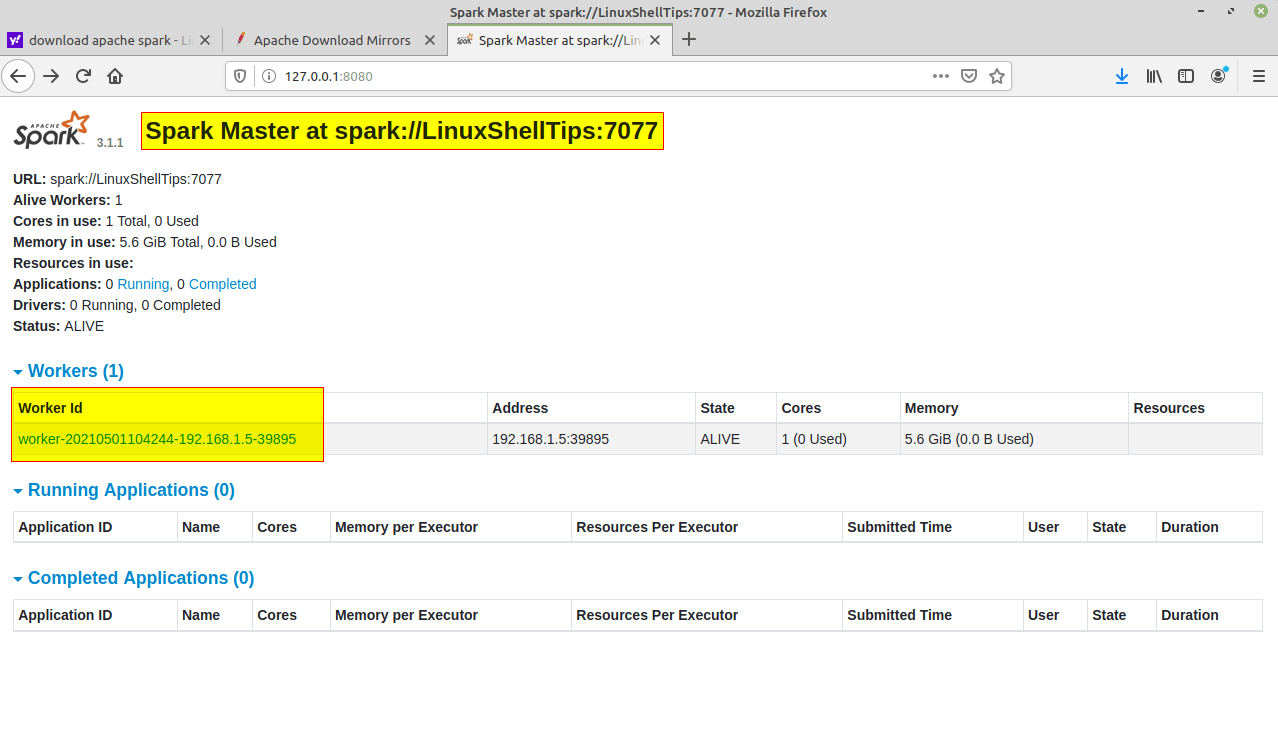
Una vez iniciado el servicio, vaya al navegador y escriba la siguiente URL de acceso a la página Spark. Desde la página, puedes ver que se inició mi servicio de maestro y esclavo.
http://localhost:8080/
OR
http://127.0.0.1:8080
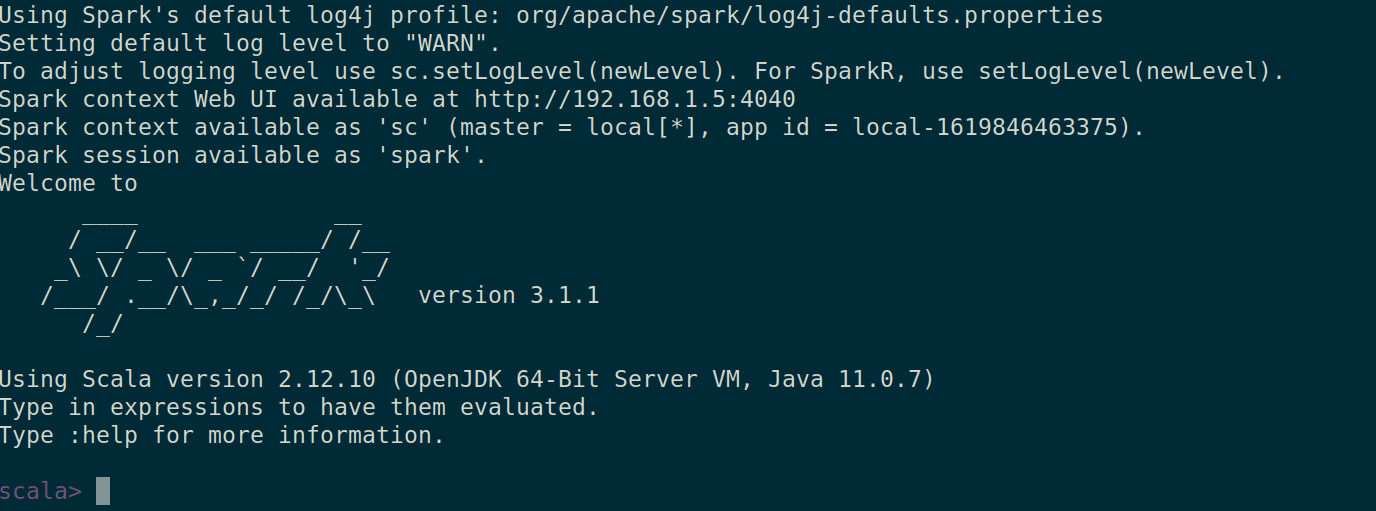
También puedes comprobar si spark-shell funciona bien ejecutando el comando spark-shell.
spark-shell
Eso es todo por este artículo. Te atraparemos con otro artículo interesante muy pronto.