Cómo instalar y configurar Apache Hadoop en un solo nodo en CentOS 7
Apache Hadoop es un marco de código abierto creado para el almacenamiento distribuido de Big Data y el procesamiento de datos en clústeres de computadoras. El proyecto se basa en los siguientes componentes:
- Hadoop Common: contiene las bibliotecas y utilidades de Java que necesitan otros módulos de Hadoop.
- HDFS – Sistema de archivos distribuido Hadoop: un sistema de archivos escalable basado en Java distribuido en múltiples nodos.
- MapReduce: marco YARN para el procesamiento paralelo de big data.
- Hadoop YARN: un marco para la gestión de recursos del clúster.

Este artículo le guiará sobre cómo instalar Apache Hadoop en un clúster de un solo nodo en CentOS 7 (también funciona para RHEL 7 y Fedora 23+ ). versiones). Este tipo de configuración también se denomina modo pseudodistribuido de Hadoop.
Paso 1: instale Java en CentOS 7
1. Antes de continuar con la instalación de Java, primero inicie sesión con un usuario root o un usuario con privilegios de root y configure el nombre de host de su máquina con el siguiente comando.
hostnamectl set-hostname master
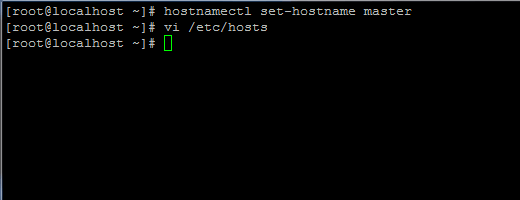
Además, agregue un nuevo registro en el archivo de hosts con el FQDN de su propia máquina para que apunte a la dirección IP de su sistema.
vi /etc/hosts
Agregue la siguiente línea:
192.168.1.41 master.hadoop.lan
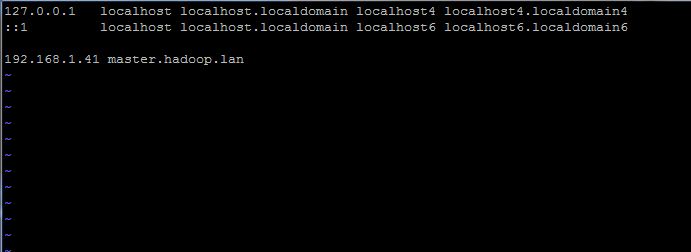
Reemplace los registros de nombre de host y FQDN anteriores con su propia configuración.
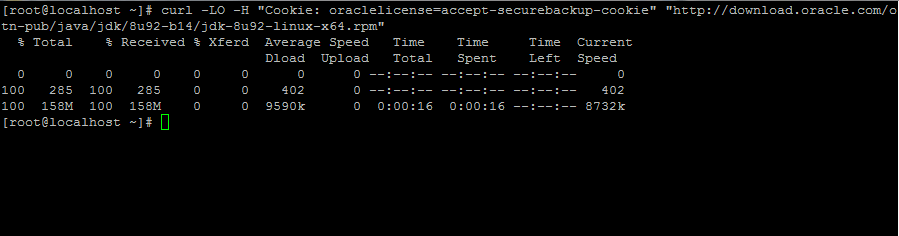
2. A continuación, vaya a la página de descarga de Oracle Java y obtenga la última versión de Java SE Development Kit 8 en su sistema con la ayuda de curl. dominio:
curl -LO -H "Cookie: oraclelicense=accept-securebackup-cookie" “http://download.oracle.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.rpm”
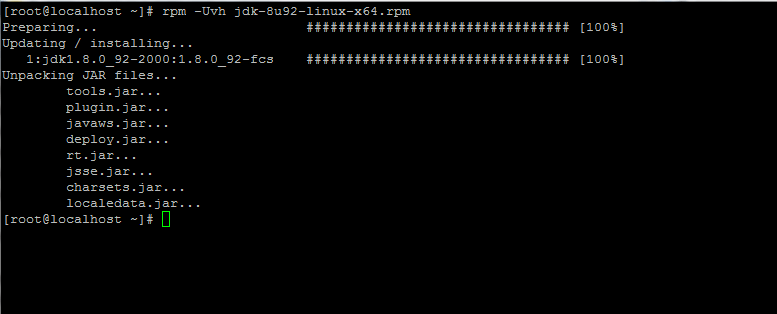
3. Una vez finalizada la descarga del binario de Java, instale el paquete emitiendo el siguiente comando:
rpm -Uvh jdk-8u92-linux-x64.rpm
Paso 2: Instale Hadoop Framework en CentOS 7
4. A continuación, cree una nueva cuenta de usuario en su sistema sin poderes de root que usaremos para la ruta de instalación de Hadoop y el entorno de trabajo. El directorio de inicio de la nueva cuenta residirá en el directorio /opt/hadoop.
useradd -d /opt/hadoop hadoop
passwd hadoop
5. En el siguiente paso, visite la página de Apache Hadoop para obtener el enlace a la última versión estable y descargar el archivo en su sistema.
curl -O http://apache.javapipe.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz

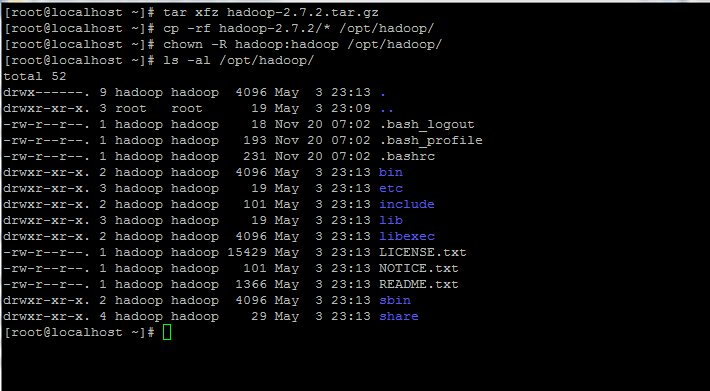
6. Extraiga el archivo y copie el contenido del directorio en la ruta de inicio de la cuenta de hadoop. Además, asegúrese de cambiar los permisos de los archivos copiados en consecuencia.
tar xfz hadoop-2.7.2.tar.gz
cp -rf hadoop-2.7.2/* /opt/hadoop/
chown -R hadoop:hadoop /opt/hadoop/
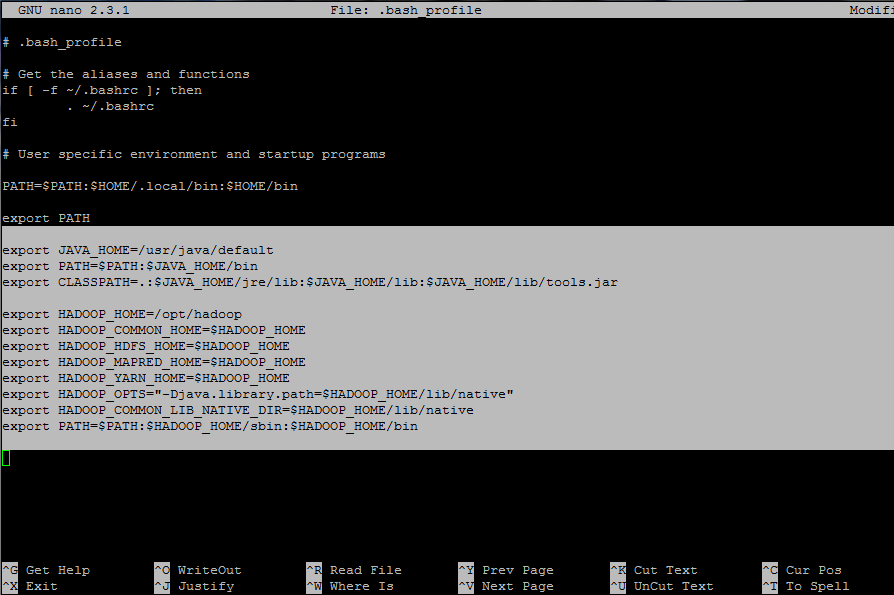
7. A continuación, inicie sesión con el usuario hadoop y configure Hadoop y las variables de entorno Java en su sistema editando el < código>.bash_profile archivo.
su - hadoop
vi .bash_profile
Agregue las siguientes líneas al final del archivo:
## JAVA env variables
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
## HADOOP env variables
export HADOOP_HOME=/opt/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
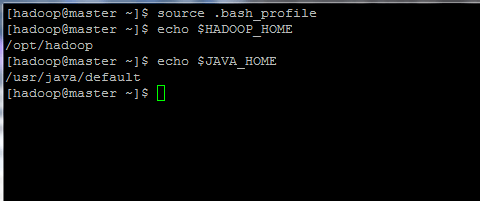
8. Ahora, inicialice las variables de entorno y verifique su estado emitiendo los siguientes comandos:
source .bash_profile
echo $HADOOP_HOME
echo $JAVA_HOME
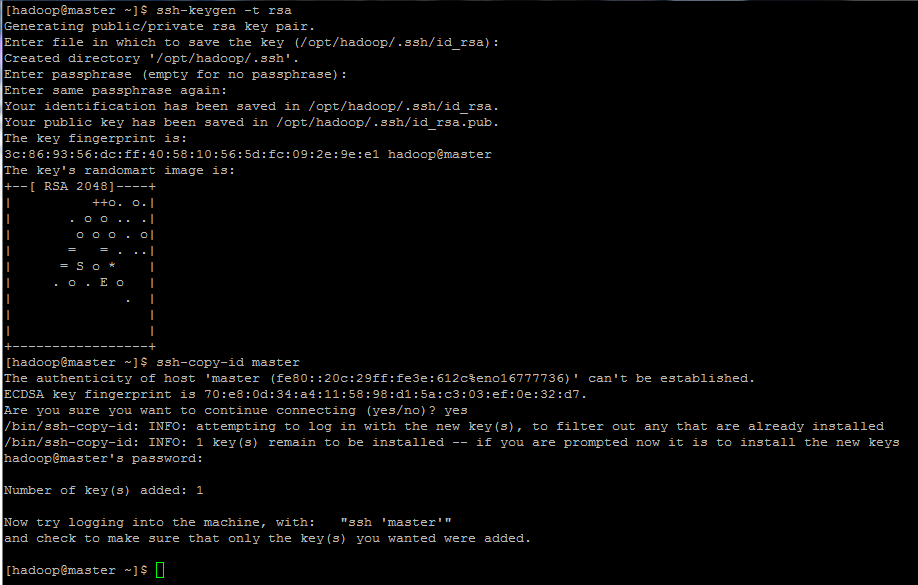
9. Finalmente, configure la autenticación basada en clave ssh para la cuenta hadoop ejecutando los siguientes comandos (reemplace el nombre de host o el FQDN > contra el comando ssh-copy-id en consecuencia).
Además, deje la frase de contraseña en blanco para iniciar sesión automáticamente a través de ssh.
ssh-keygen -t rsa
ssh-copy-id master.hadoop.lan