LFCS: Monitorear el uso de recursos de los procesos de Linux y establecer límites de proceso por usuario - Parte 14
Debido a las recientes modificaciones en los objetivos del examen de certificación LFCS vigentes a partir del 2 de febrero de 2016, estamos agregando los artículos necesarios a la serie LFCS publicada aquí. Para prepararse para este examen, le recomendamos encarecidamente que realice también la serie LFCE.

Todo administrador de sistemas Linux necesita saber cómo verificar la integridad y disponibilidad del hardware, los recursos y los procesos clave. Además, establecer límites de recursos por usuario también debe ser parte de su conjunto de habilidades.
En este artículo exploraremos algunas formas de garantizar que tanto el hardware como el software del sistema se comporten correctamente para evitar posibles problemas que puedan provocar tiempos de inactividad inesperados en la producción y pérdidas de dinero.
Estadísticas de procesadores de informes de Linux
Con mpstat puede ver las actividades de cada procesador individualmente o del sistema en su conjunto, como una instantánea única o de forma dinámica.
Para utilizar esta herramienta, necesitará instalar sysstat:
yum update && yum install sysstat [On CentOS based systems]
aptitutde update && aptitude install sysstat [On Ubuntu based systems]
zypper update && zypper install sysstat [On openSUSE systems]
Lea más sobre sysstat y sus utilidades en Aprenda Sysstat y sus utilidades mpstat, pidstat, iostat y sar en Linux
Una vez que haya instalado mpstat, utilícelo para generar informes de estadísticas de procesadores.
Para mostrar 3 informes globales de utilización de CPU (-u) para todas las CPU (como lo indica -P ALL) en un intervalo de 2 segundos , hacer:
mpstat -P ALL -u 2 3
Salida de muestra
Linux 3.19.0-32-generic (linux-console.net) Wednesday 30 March 2016 _x86_64_ (4 CPU)
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
Para ver las mismas estadísticas para una CPU específica (CPU 0 en el siguiente ejemplo), utilice:
mpstat -P 0 -u 2 3
Salida de muestra
Linux 3.19.0-32-generic (linux-console.net) Wednesday 30 March 2016 _x86_64_ (4 CPU)
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
El resultado de los comandos anteriores muestra estas columnas:
CPU: número de procesador como un número entero, o la palabra todo como un promedio de todos los procesadores.%usr: porcentaje de utilización de la CPU al ejecutar aplicaciones de nivel de usuario.%nice: Igual que%usr, pero con buena prioridad.%sys: Porcentaje de utilización de CPU que se produjo al ejecutar aplicaciones del kernel. Esto no incluye el tiempo dedicado a lidiar con interrupciones o manejar hardware.%iowait: Porcentaje de tiempo en el que la CPU determinada (o todas) estuvo inactiva, durante el cual hubo una operación de E/S con uso intensivo de recursos programada en esa CPU. Puede encontrar una explicación más detallada (con ejemplos) aquí.%irq: Porcentaje de tiempo dedicado a atender interrupciones de hardware.%soft: Igual que%irq, pero con interrupciones de software.%steal: Porcentaje de tiempo invertido en espera involuntaria (robo o tiempo robado) cuando una máquina virtual, como invitada, está "ganándose" la atención del hipervisor mientras compite por las CPU. Este valor debe mantenerse lo más pequeño posible. Un valor alto en este campo significa que la máquina virtual se está deteniendo, o pronto lo estará.%guest: Porcentaje de tiempo dedicado a ejecutar un procesador virtual.%idle: porcentaje de tiempo en el que las CPU no ejecutaban ninguna tarea. Si observa un valor bajo en esta columna, es una indicación de que el sistema está sometido a una carga pesada. En ese caso, deberá observar más de cerca la lista de procesos, como veremos en un minuto, para determinar qué lo está causando.
Para poner el procesador bajo una carga algo alta, ejecute los siguientes comandos y luego ejecute mpstat (como se indica) en una terminal separada:
dd if=/dev/zero of=test.iso bs=1G count=1
mpstat -u -P 0 2 3
ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
mpstat -u -P 0 2 3
Finalmente, compárelo con la salida de mpstat en circunstancias "normales":
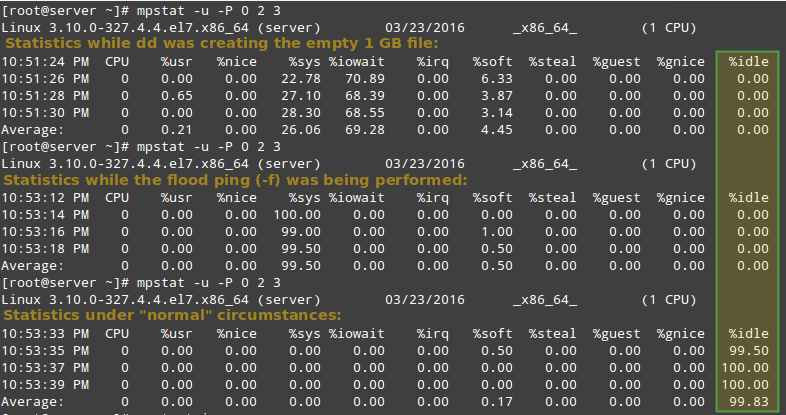
Como puede ver en la imagen de arriba, la CPU 0 estuvo bajo una carga pesada durante los dos primeros ejemplos, como lo indica la columna %idle.
En la siguiente sección discutiremos cómo identificar estos procesos que consumen muchos recursos, cómo obtener más información sobre ellos y cómo tomar las medidas adecuadas.
Informes de procesos de Linux
Para enumerar los procesos clasificándolos por uso de CPU, usaremos el conocido comando ps con -eo (para seleccionar todos los procesos con formato definido por el usuario) y --sort (para especificar un orden de clasificación personalizado), así:
ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
El comando anterior solo mostrará el PID, PPID, el comando asociado con el proceso y el porcentaje de uso de CPU y RAM ordenado por el porcentaje de uso de CPU en orden descendente. . Cuando se ejecuta durante la creación del archivo .iso, aquí están las primeras líneas del resultado:
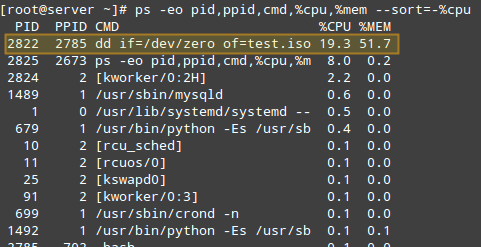
Una vez que hayamos identificado un proceso de interés (como el que tiene PID=2822), podemos navegar a /proc/PID (/proc/2822 en este caso) y hacer un listado del directorio.
Este directorio es donde se guardan varios archivos y subdirectorios con información detallada sobre este proceso en particular mientras se ejecuta.
Por ejemplo:
/proc/2822/iocontiene estadísticas de IO para el proceso (número de caracteres y bytes leídos y escritos, entre otros, durante las operaciones de IO)./proc/2822/attr/currentmuestra los atributos de seguridad SELinux actuales del proceso./proc/2822/cgroupdescribe los grupos de control (cgroups para abreviar) a los que pertenece el proceso si la opción de configuración del kernel CONFIG_CGROUPS está habilitada, que puede verificar con:
cat /boot/config-$(uname -r) | grep -i cgroups
Si la opción está habilitada, debería ver:
CONFIG_CGROUPS=y
Usando cgroups puede administrar la cantidad de uso de recursos permitido por proceso, como se explica en los Capítulos 1 a 4 de la guía de administración de recursos de Red Hat Enterprise Linux 7, en el Capítulo 9 del Análisis del sistema openSUSE. y guía de ajuste, y en la sección Grupos de control de la documentación del servidor Ubuntu 14.04.
El /proc/2822/fd es un directorio que contiene un enlace simbólico para cada descriptor de archivo que el proceso ha abierto. La siguiente imagen muestra esta información para el proceso que se inició en tty1 (la primera terminal) para crear la imagen .iso:
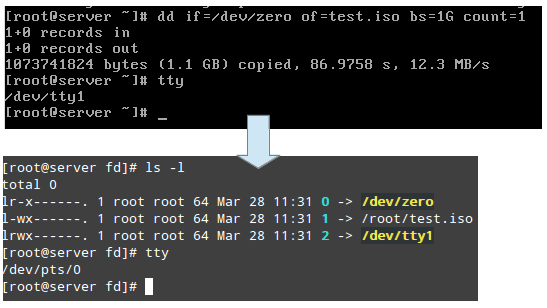
La imagen de arriba muestra que stdin (descriptor de archivo 0), stdout (descriptor de archivo 1) y stderr (descriptor de archivo 2) se asignan a /dev/zero, /root/test.iso y /dev/tty1, respectivamente.
Puede encontrar más información sobre /proc en el documento “El sistema de archivos /proc” conservado y mantenido por Kernel.org y en el Manual del programador de Linux.
Establecer límites de recursos por usuario en Linux
Si no tiene cuidado y permite que cualquier usuario ejecute una cantidad ilimitada de procesos, eventualmente puede experimentar un apagado inesperado del sistema o quedar bloqueado cuando el sistema entra en un estado inutilizable. Para evitar que esto suceda, debe establecer un límite en la cantidad de procesos que los usuarios pueden iniciar.
Para hacer esto, edite /etc/security/limits.conf y agregue la siguiente línea al final del archivo para establecer el límite:
* hard nproc 10
El primer campo se puede utilizar para indicar un usuario, un grupo o todos ellos (*), mientras que el segundo campo impone un límite estricto en el número de procesos (nproc) a 10. Para aplicar los cambios, basta con cerrar sesión y volver a iniciarla.
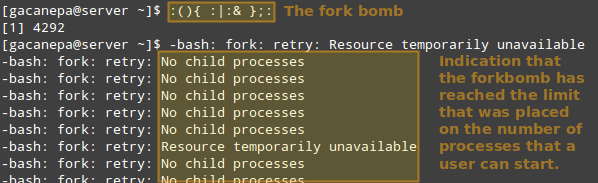
Por lo tanto, veamos qué sucede si un determinado usuario que no sea root (ya sea legítimo o no) intenta iniciar una bomba shell fork. Si no hubiéramos implementado límites, esto iniciaría inicialmente dos instancias de una función y luego duplicaría cada una de ellas en un bucle interminable. Por lo tanto, eventualmente haría que su sistema se ralentizara.
Sin embargo, con la restricción anterior implementada, la bomba fork no tiene éxito, pero el usuario seguirá bloqueado hasta que el administrador del sistema finalice el proceso asociado con ella:
CONSEJO: Otras posibles restricciones posibles gracias a ulimit están documentadas en el archivo limits.conf.
Otras herramientas de gestión de procesos de Linux
Además de las herramientas analizadas anteriormente, es posible que un administrador del sistema también necesite:
a) Modificar la prioridad de ejecución (uso de recursos del sistema) de un proceso utilizando renice. Esto significa que el kernel asignará más o menos recursos del sistema al proceso según la prioridad asignada (un número comúnmente conocido como “amabilidad” en un rango de -20 a
Cuanto menor sea el valor, mayor será la prioridad de ejecución. Los usuarios habituales (excepto root) sólo pueden modificar la calidad de los procesos que poseen a un valor más alto (lo que significa una prioridad de ejecución más baja), mientras que root puede modificar este valor para cualquier proceso y puede aumentarlo o disminuirlo.
La sintaxis básica de renice es la siguiente:
renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
Si el argumento después del nuevo valor de prioridad no está presente (vacío), se establece en PID de forma predeterminada. En ese caso, la bondad del proceso con PID=identificador se establece en
b) Interrumpir la ejecución normal de un proceso cuando sea necesario. Esto se conoce comúnmente como “matar” el proceso. En el fondo, esto significa enviar una señal al proceso para que finalice su ejecución correctamente y libere los recursos utilizados de manera ordenada.
Para finalizar un proceso, utilice el comando kill de la siguiente manera:
kill PID
Alternativamente, puede usar pkill para finalizar todos los procesos de un propietario determinado (-u), o de un propietario de grupo (-G), o incluso aquellos procesos que tienen un PPID. en común
pkill [options] identifier
Por ejemplo,
pkill -G 1000
eliminará todos los procesos propiedad del grupo con GID=1000.
Y,
pkill -P 4993
matará todos los procesos cuyo PPID sea 4993.
Antes de ejecutar un pkill, es una buena idea probar los resultados con pgrep primero, quizás usando también la opción -l para enumerar los nombres de los procesos. Toma las mismas opciones pero solo devuelve los PID de los procesos (sin realizar ninguna acción adicional) que se eliminarían si se usa pkill.
pgrep -l -u gacanepa
Esto se ilustra en la siguiente imagen:

Resumen
En este artículo hemos explorado algunas formas de monitorear el uso de recursos para verificar la integridad y disponibilidad de componentes críticos de hardware y software en un sistema Linux.
También hemos aprendido cómo tomar las medidas adecuadas (ya sea ajustando la prioridad de ejecución de un proceso determinado o finalizándolo) en circunstancias inusuales.
Esperamos que los conceptos explicados en este tutorial hayan sido útiles. Si tiene alguna pregunta o comentario, no dude en comunicarse con nosotros mediante el formulario de contacto a continuación.