Cómo sincronizar la configuración del clúster y verificar la configuración de conmutación por error en los nodos - Parte 4
Hola gente. En primer lugar, mis disculpas por el retraso de la última parte de esta serie de grupos. Pongámonos manos a la obra sin demorarnos más.
Como muchos de ustedes han completado las tres partes anteriores, les informaré lo que hemos completado hasta ahora. Ahora ya tenemos suficiente conocimiento para instalar y configurar paquetes de clúster para dos nodos y habilitar la protección y la conmutación por error en un entorno de clúster.

Puedes consultar mis partes anteriores si no lo recuerdas, ya que tomó un poco más de tiempo publicar la última parte.
Introducción a la agrupación en clústeres de Linux y sus ventajas y desventajas: Parte 1
Cómo instalar y configurar un clúster con dos nodos en Linux – Parte 2
Cercado y adición de una conmutación por error a la agrupación en clústeres: Parte 3
Comenzaremos agregando recursos al clúster. En este caso podemos agregar un sistema de archivos o un servicio web según sus necesidades. Ahora tengo la partición /dev/sda3 montada en /x01 que deseo agregar como recurso del sistema de archivos.
1. Utilizo el siguiente comando para agregar un sistema de archivos como recurso:
ccs -h 172.16.1.250 --addresource fs name=my_fs device=/dev/mapper/tecminttest_lv_vol01 mountpoint=/x01 fstype=ext3

Además, si también desea agregar un servicio, puede hacerlo utilizando la siguiente metodología. Emita el siguiente comando.
ccs -h 172.16.1.250 --addservice my_web domain=testdomain recovery=relocate autostart=1
Puede verificarlo viendo el archivo cluster.conf como lo hicimos en lecciones anteriores.
2. Ahora ingrese la siguiente entrada en el archivo cluster.conf para agregar una etiqueta de referencia al servicio.
<fs ref="my_fs"/>

3. Todo listo. No, veremos cómo podemos sincronizar las configuraciones que hicimos para agrupar entre los 2 nodos que tenemos. El siguiente comando hará lo necesario.
ccs -h 172.16.1.250 --sync --activate
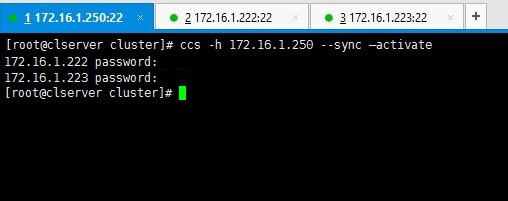
Nota: Ingrese las contraseñas que configuramos para ricci en las primeras etapas cuando estábamos instalando paquetes.
Puede verificar sus configuraciones usando el siguiente comando.
ccs -h 172.16.1.250 --checkconf
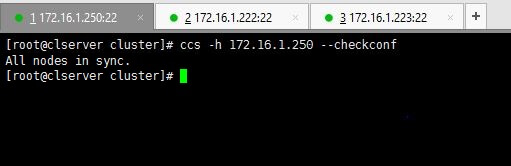
4. Ahora es el momento de poner en marcha todo. Puede utilizar uno de los siguientes comandos como prefiera.
Para iniciar solo un nodo, use el comando con la IP relevante.
ccs -h 172.16.1.222 start
O si desea iniciar todos los nodos, utilice la opción --startall de la siguiente manera.
ccs -h 172.16.1.250 –startall
Puede usar stop o --stopall si necesita detener el clúster.
En un escenario como si quisiera iniciar el clúster sin habilitar los recursos (los recursos se habilitarán automáticamente cuando se inicie el clúster), como una situación en la que ha deshabilitado intencionalmente los recursos en un nodo en particular para deshabilitar los bucles de cerca, usted No quiero habilitar esos recursos cuando se inicia el clúster.
Para ello, puede utilizar el siguiente comando que inicia el clúster pero no habilita los recursos.
ccs -h 172.16.1.250 --startall --noenable
5. Una vez iniciado el clúster, puede ver las estadísticas emitiendo el comando clustat.
clustat

El resultado anterior dice que hay dos nodos en el clúster y ambos están en funcionamiento en este momento.
6. Puede recordar que agregamos un mecanismo de conmutación por error en nuestras lecciones anteriores. ¿Quieres comprobar que funciona? Así es como lo haces. Fuerce el apagado de un nodo y busque las estadísticas del clúster utilizando el comando clustat para conocer los resultados de la conmutación por error.
He cerrado mi node02server(172.16.1.223) usando el comando shutdown -h now. Luego ejecuté el comando clustat desde mi cluster_server(172.16.1.250).

El resultado anterior le aclara que el nodo 1 está en línea mientras que el nodo 2 se ha desconectado cuando lo cerramos. Sin embargo, el servicio y el sistema de archivos que compartimos todavía están en línea, como puede ver si lo verifica en node01, que está en línea.
df -h /x01

Consulte el archivo cluster.conf con el conjunto de configuración completo relevante para nuestra configuración utilizada para tecmint.
<?xml version="1.0"?>
<cluster config_version="15" name="tecmint_cluster">
<fence_daemon post_join_delay="10"/>
<clusternodes>
<clusternode name="172.16.1.222" nodeid="1">
<fence>
<method name="Method01">
<device name="tecmintfence"/>
</method>
</fence>
</clusternode>
<clusternode name="172.16.1.223" nodeid="2">
<fence>
<method name="Method01">
<device name="tecmintfence"/>
</method>
</fence>
</clusternode>
</clusternodes>
<cman/>
<fencedevices>
<fencedevice agent="fence_virt" name="tecmintfence"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="tecmintfod" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="172.16.1.222" priority="1"/>
<failoverdomainnode name="172.16.1.223" priority="2"/>
</failoverdomain>
</failoverdomains>
<resources>
<fs device="/dev/mapper/tecminttest_lv_vol01" fstype="ext3" mountpoint="/x01" name="my_fs"/>
</resources>
<service autostart="1" domain="testdomain" name="my_web" recovery="relocate"/>
<fs ref="my_fs"/>
</rm>
</cluster>
Espero que hayas disfrutado toda la serie de lecciones de agrupación. Manténgase en contacto con tecmint para obtener guías más útiles todos los días y no dude en comentar sus ideas y consultas.