LFCS #1: Cómo utilizar el comando 'sed' para la manipulación de archivos en Linux
La Fundación Linux anunció la certificación LFCS (Linux Foundation Certified Sysadmin), un nuevo programa que tiene como objetivo ayudar a personas de todo el mundo a obtener la certificación en tareas de administración de sistemas básicas a intermedias para sistemas Linux.
Esto incluye soporte para sistemas y servicios en ejecución, junto con resolución y análisis de problemas de primera mano, y toma de decisiones inteligentes para derivar problemas a los equipos de ingeniería.
A partir de la última revisión del 11 de agosto de 2023, hemos contabilizado meticulosamente los dominios y competencias, alineándonos con la fecha de vigencia del 11 de mayo de 2023, como lo declaró oficialmente la Fundación Linux.
La serie se titulará Preparación para las partes LFCS (Linux Foundation Certified Sysadmin) 1 a la 33 y cubrirá las siguientes temas:
- Part 1
Cómo utilizar el comando 'Sed' para manipular archivos en Linux
- Part 2
-
Cómo instalar y usar Vi/Vim en Linux
- Part 3
Cómo comprimir archivos y directorios y buscar archivos en Linux
- Part 4
Particionar dispositivos de almacenamiento, formatear sistemas de archivos y configurar la partición de intercambio
- Part 5
Montar/desmontar sistemas de archivos locales y de red (Samba y NFS) en Linux
- Part 6
Ensamblaje de particiones como dispositivos RAID: creación y administración de copias de seguridad del sistema
- Part 7
Gestión del proceso y los servicios de inicio del sistema (SysVinit, Systemd y Upstart)
- Part 8
Cómo administrar usuarios y grupos, permisos de archivos y acceso a Sudo
- Part 9
Gestión de paquetes de Linux con Yum, RPM, Apt, Dpkg, Aptitude y Zypper
- Part 10
Aprendizaje de secuencias de comandos de Shell básicas y solución de problemas del sistema de archivos
- Part 11
Cómo administrar y crear LVM usando los comandos vgcreate, lvcreate y lvextend
- Part 12
-
Cómo explorar Linux con herramientas y documentación de ayuda instaladas
- Part 13
Cómo configurar y solucionar problemas de Grand Unified Bootloader (GRUB)
- Part 14
Supervise el uso de recursos de los procesos de Linux y establezca límites de proceso por usuario
- Part 15
Cómo configurar o modificar los parámetros de tiempo de ejecución del kernel en sistemas Linux
- Part 16
Implementación de control de acceso obligatorio con SELinux o AppArmor en Linux
- Part 17
Cómo configurar listas de control de acceso (ACL) y cuotas de disco para usuarios y grupos
- Part 18
Instalación de servicios de red y configuración del inicio automático al arrancar
- Part 19
Una guía definitiva para configurar un servidor FTP para permitir inicios de sesión anónimos
- Part 20
Configure un servidor DNS de almacenamiento en caché recursivo básico y configure zonas para el dominio
- Part 21
Cómo instalar, proteger y ajustar el rendimiento del servidor de base de datos MariaDB
- Part 22
-
Cómo instalar y configurar el servidor NFS para compartir sistemas de archivos
- Part 23
Cómo configurar Apache con alojamiento virtual basado en nombres con certificado SSL
- Part 24
Cómo configurar un firewall de Iptables para permitir el acceso remoto a servicios en Linux
- Part 25
Cómo convertir un Linux en un enrutador para manejar el tráfico de forma estática y dinámica
- Part 26
Cómo configurar sistemas de archivos cifrados e intercambiarlos utilizando la herramienta Cryptsetup
- Part 27
Cómo monitorear el uso del sistema, las interrupciones y solucionar problemas de servidores Linux
- Part 28
Cómo configurar un repositorio de red para instalar o actualizar paquetes
- Part 29
Cómo auditar el rendimiento, la seguridad y la resolución de problemas de la red
- Part 30
Cómo instalar y administrar máquinas virtuales y contenedores
- Part 31
Aprenda los conceptos básicos de Git para gestionar proyectos de forma eficiente
- Part 32
Una guía para principiantes para configurar direcciones IPv4 e IPv6 en Linux
- Part 33
Una guía para principiantes para crear enlaces y puentes de red en Ubuntu
Esta publicación es la Parte 1 de una serie de 33 tutoriales, que cubrirá los dominios y competencias necesarios que se requieren para el examen de certificación LFCS. Dicho esto, enciende tu terminal y comencemos.
Procesamiento de flujos de texto en Linux
Linux trata la entrada y salida de los programas como flujos (o secuencias) de caracteres. Para comenzar a comprender la redirección y las canalizaciones, primero debemos comprender los tres tipos más importantes de flujos de E/S (entrada y salida), que en realidad son archivos especiales (por convención en UNIX y Linux, flujos de datos y periféricos, o archivos de dispositivos, también se tratan como archivos normales).
La diferencia entre > (operador de redirección) y | (operador de canalización) es que mientras el primero conecta un comando con un archivo, el segundo conecta la salida de un comando con otro. dominio.
command > file
command1 | command2
Dado que el operador de redirección crea o sobrescribe archivos de forma silenciosa, debemos usarlo con extrema precaución y nunca confundirlo con una canalización.
Una ventaja de las canalizaciones en los sistemas Linux y UNIX es que no hay ningún archivo intermedio involucrado con una canalización: la salida estándar del primer comando no se escribe en un archivo y luego el segundo comando la lee.
Para los siguientes ejercicios de práctica utilizaremos el poema “Un niño feliz” (autor anónimo).
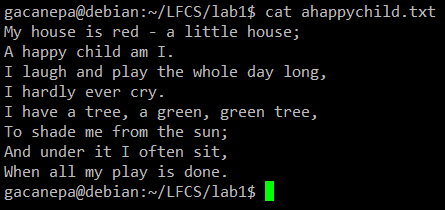
Usando el comando sed
El nombre sed es la abreviatura de editor de secuencias. Para aquellos que no están familiarizados con el término, se utiliza un editor de secuencias para realizar transformaciones de texto básicas en una secuencia de entrada (un archivo o entrada de una canalización).
Cambiar minúsculas a mayúsculas en un archivo
El uso más básico (y popular) de sed es la sustitución de caracteres. Comenzaremos cambiando cada aparición de y minúscula a Y MAYÚSCULA y redirigiendo la salida a ahappychild2.txt.
El indicador g indica que sed debe realizar la sustitución de todas las instancias de term en cada línea del archivo. Si se omite este indicador, sed reemplazará solo la primera aparición del término en cada línea.
Sintaxis básica de Sed:
sed ‘s/term/replacement/flag’ file
Nuestro ejemplo:
sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt

Buscar y reemplazar Word en un archivo
Si desea buscar o reemplazar un carácter especial (como /, \, &), deberá omitirlo en el término o cadenas de reemplazo, con una barra invertida.
Por ejemplo, sustituiremos la palabra y por un signo comercial. Al mismo tiempo, reemplazaremos la palabra I por You cuando la primera se encuentre al principio de una línea.
sed 's/and/\&/g;s/^I/You/g' ahappychild.txt

En el comando anterior, un ^ (signo de intercalación) es una expresión regular muy conocida que se utiliza para representar el comienzo de una línea.
Como puede ver, podemos combinar dos o más comandos de sustitución (y usar expresiones regulares dentro de ellos) separándolos con un punto y coma y encerrando el conjunto entre comillas simples.
Imprimir líneas seleccionadas desde un archivo
Otro uso de sed es mostrar (o eliminar) una parte seleccionada de un archivo. En el siguiente ejemplo, mostraremos las primeras 5 líneas de /var/log/messages del 8 de junio.
sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
Tenga en cuenta que, de forma predeterminada, sed imprime cada línea. Podemos anular este comportamiento con la opción -n y luego decirle a sed que imprima (indicado por p) solo la parte del archivo (o la tubería) que coincide con el patrón. (8 de junio al inicio de la línea en el primer caso y líneas 1 a 5 inclusive en el segundo caso).
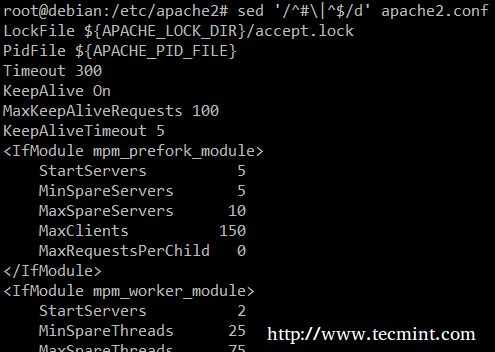
Finalmente, puede resultar útil al inspeccionar scripts o archivos de configuración inspeccionar el código en sí y omitir comentarios. El siguiente resumen sed elimina (d) líneas en blanco o aquellas que comienzan con # (el carácter | indica un OR< booleano entre las dos expresiones regulares).
sed '/^#\|^$/d' apache2.conf
comando único
El comando uniq nos permite informar o eliminar líneas duplicadas en un archivo, escribiendo en stdout de forma predeterminada. Debemos tener en cuenta que uniq no detecta líneas repetidas a menos que sean adyacentes.
Por lo tanto, uniq se usa comúnmente junto con un sort anterior (que se usa para ordenar líneas de archivos de texto). De forma predeterminada, sort toma el primer campo (separado por espacios) como campo clave. Para especificar un campo clave diferente, necesitamos usar la opción -k.
Ejemplos de comandos Uniq
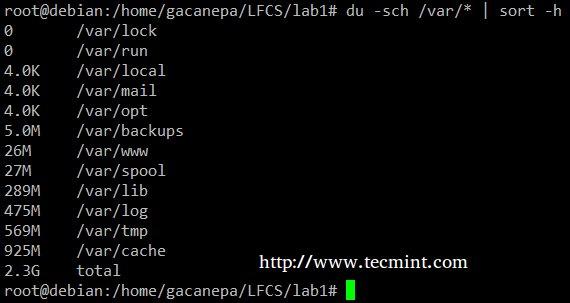
El comando du -sch /path/to/directory/* devuelve el uso de espacio en disco por subdirectorios y archivos dentro del directorio especificado en formato legible por humanos (también muestra un total por directorio), y no Ordene la salida por tamaño, pero por subdirectorio y nombre de archivo.
Podemos usar el siguiente comando para ordenar por tamaño.
du -sch /var/* | sort –h
Puede contar el número de eventos en un registro por fecha diciéndole a uniq que realice la comparación utilizando los primeros 6 caracteres (-w 6) de cada línea (donde está la fecha). se especifica), y anteponiendo cada línea de salida con el número de apariciones (-c) con el siguiente comando.
cat /var/log/mail.log | uniq -c -w 6

Finalmente, puedes combinar sort y uniq (como suelen ser). Considere el siguiente archivo con una lista de donantes, fecha de donación y monto. Supongamos que queremos saber cuántos donantes únicos hay.
Usaremos el siguiente comando cat para cortar el primer campo (los campos están delimitados por dos puntos), ordenar por nombre y eliminar líneas duplicadas.
cat sortuniq.txt | cut -d: -f1 | sort | uniq

Comando grep
El comando grep busca archivos de texto o (salida del comando) la aparición de una expresión regular especificada y genera cualquier línea que contenga una coincidencia con la salida estándar.
Ejemplos de comandos grep
Muestra la información de /etc/passwd para el usuario gacanepa, ignorando mayúsculas y minúsculas.
grep -i gacanepa /etc/passwd

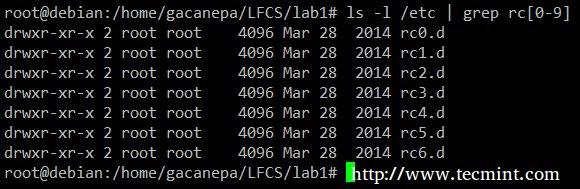
Muestra todo el contenido de /etc cuyo nombre comienza con rc seguido de cualquier número.
ls -l /etc | grep rc[0-9]
Uso del comando tr
El comando tr se puede utilizar para traducir (cambiar) o eliminar caracteres de la entrada estándar y escribir el resultado en la salida estándar.
Cambie todo en minúsculas a mayúsculas en el archivo sortuniq.txt.
cat sortuniq.txt | tr [:lower:] [:upper:]

Apriete el delimitador en la salida de ls –l a un solo espacio.
ls -l | tr -s ' '

Cortar uso del comando
El comando cut extrae partes de líneas de entrada (de stdin o archivos) y muestra el resultado en la salida estándar, según el número de bytes (opción -b), caracteres (-c), o campos (
En este último caso (basado en campos), el separador de campos predeterminado es una pestaña, pero se puede especificar un delimitador diferente usando la opción -d.
Ejemplos de comandos de corte
Extraiga las cuentas de usuario y los shells predeterminados asignados a ellas desde /etc/passwd (la opción –d nos permite especificar el delimitador de campo y el –f El modificador indica qué campos se extraerán.
cat /etc/passwd | cut -d: -f1,7

En resumen, crearemos un flujo de texto que consta del primer y tercer archivo que no estén en blanco de la salida del último comando. Usaremos grep como primer filtro para verificar las sesiones del usuario gacanepa, luego apretaremos los delimitadores a un solo espacio (tr -s ' ' ).
A continuación, extraeremos el primer y tercer campo con cortar y, finalmente, ordenaremos por el segundo campo (direcciones IP en este caso) que muestra ser único.
last | grep gacanepa | tr -s ' ' | cut -d' ' -f1,3 | sort -k2 | uniq

El comando anterior muestra cómo se pueden combinar múltiples comandos y canalizaciones para obtener datos filtrados según nuestros deseos. Siéntase libre de ejecutarlo también por partes, para ayudarle a ver el resultado que se canaliza de un comando al siguiente (¡por cierto, esta puede ser una gran experiencia de aprendizaje!).
Resumen
Aunque este ejemplo (junto con el resto de los ejemplos del tutorial actual) puede no parecer muy útil a primera vista, es un buen punto de partida para comenzar a experimentar con comandos que se utilizan para crear, editar y manipular archivos desde Linux. línea de comando.
No dudes en dejar tus preguntas y comentarios a continuación: ¡serán muy apreciados!
El libro electrónico LFCS ya está disponible para su compra. ¡Solicite su copia hoy y comience su viaje para convertirse en un administrador certificado de sistemas Linux!
| Product Name | Price | Buy |
|---|---|---|
| The Linux Foundation’s LFCS Certification Preparation Guide | $19.99 | [Buy Now] |
Por último, pero no menos importante, considere comprar su vale de examen utilizando los siguientes enlaces para ganarnos una pequeña comisión, que nos ayudará a mantener este libro actualizado.