3 formas de crear un disco de inicio USB de arranque de Ubuntu
Crear una unidad USB de arranque es una de las formas preferidas de probar e instalar un sistema operativo Linux en una PC. Esto se debe a que la mayoría de las PC modernas ya no vienen con una unidad de DVD. Además, las unidades USB son fácilmente portátiles y menos delicadas que un CD/DVD.
Abundan muchas herramientas gráficas que pueden ayudarle a crear una unidad USB de arranque. Una de las herramientas más utilizadas es Rufus, una herramienta sencilla pero muy eficaz. Lamentablemente, sólo está disponible para sistemas Windows.
Afortunadamente, Ubuntu viene con su propia herramienta llamada Startup Disk Creator. La herramienta es fácil de usar y le permite crear un disco USB de Ubuntu de arranque en poco tiempo.
Con una unidad USB de Ubuntu de arranque puedes realizar las siguientes operaciones:
- Instala Ubuntu en tu PC.
- Pruebe el escritorio de Ubuntu sin instalarlo en su disco duro.
- Inicie Ubuntu en otra PC y ejecútelo.
- Realice operaciones de diagnóstico como reparar o arreglar una configuración rota.
Con eso en mente, veamos cómo puedes crear un disco de inicio Ubuntu USB de arranque.
Requisitos
Para este ejercicio, asegúrese de tener los siguientes requisitos previos antes de comenzar:
- Una unidad USB: mínimo 4 GB.
- Imagen ISO de Ubuntu (usaremos Ubuntu 20.04 ISO).
- Una conexión a Internet estable para descargar la imagen ISO de Ubuntu, si no tiene una.
En esta guía, exploraremos tres métodos que puede utilizar para crear un disco de inicio Ubuntu USB de arranque.
En esta página:
- Cómo crear un disco de inicio USB de arranque de Ubuntu usando una herramienta gráfica
- Cómo crear un disco de inicio USB de arranque de Ubuntu usando el comando ddrescue
- Cómo crear un disco de inicio USB de arranque de Ubuntu usando el comando dd
Cambiemos de tema y veamos cómo se puede crear una startup de Ubuntu.
Creación de un disco de inicio USB de Ubuntu mediante una herramienta gráfica
El Creador de disco de inicio es la herramienta nativa de Ubuntu que viene preinstalada en cada versión moderna de Ubuntu. Permite al usuario crear una unidad Live USB a partir de una imagen ISO de una forma sencilla pero rápida y eficaz.
Para iniciar el creador de Startup Disk, haga clic en "Actividades" en la esquina superior izquierda de su escritorio y busque la herramienta en el administrador de aplicaciones como se muestra. A continuación, haga clic en la opción "Startup Disk Creator" para iniciarlo.
Una vez iniciado, aparecerá una ventana como se muestra. La sección superior muestra la ruta de la imagen ISO, la versión del archivo ISO y su tamaño. Si todas las opciones están bien, continúe y presione la opción "Crear disco de inicio" para comenzar el proceso de creación de la unidad USB de arranque.
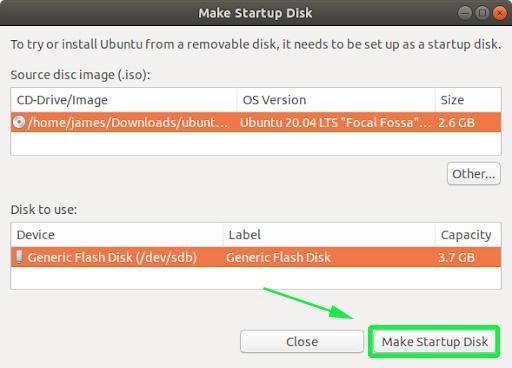
A partir de entonces, recibirá una notificación emergente que le preguntará si desea continuar con la creación o cancelarla. Haga clic en la opción "Sí" para inicializar la creación de la unidad de arranque. Proporcione su contraseña para autenticarse e iniciar el proceso.

La herramienta Startup Disk Creator comenzará a escribir la imagen del disco en la unidad USB. Esto debería tardar sólo unos minutos en completarse.

Una vez completado, recibirá la notificación emergente a continuación indicando que todo salió bien. Para probar Ubuntu, haga clic en el botón "Probar disco". Si desea continuar y comenzar a utilizar la unidad de arranque, simplemente haga clic en "Salir".

Creación de un disco de inicio USB de Ubuntu mediante el comando DDrescue
La herramienta ddrescue es una popular herramienta de recuperación de datos que puede utilizar para recuperar datos de dispositivos de almacenamiento fallidos, como discos duros, pendrives, etc. Además, puede utilizar la herramienta ddrescue. > herramienta para convertir una imagen ISO en una unidad USB de inicio.
Para instalar ddrescue en sistemas Ubuntu/Debian ejecute el comando.
sudo apt install gddrescue
NOTA: Los repositorios se refieren a él como gddrescue. Sin embargo, cuando lo invoque en el terminal utilice ddrescue.
A continuación, debemos verificar el volumen del dispositivo de bloque de la unidad USB. Para lograr esto, use el comando lsblk como se muestra a continuación:
lsblk
El siguiente resultado confirma que nuestra unidad USB está indicada por /dev/sdb.

Ahora use la sintaxis siguiente para crear una memoria USB de arranque.
sudo ddrescue path/to/.iso /dev/sdx --force -D
Por ejemplo, para crear un disco de inicio de Ubuntu 20.04, ejecutamos el siguiente comando.
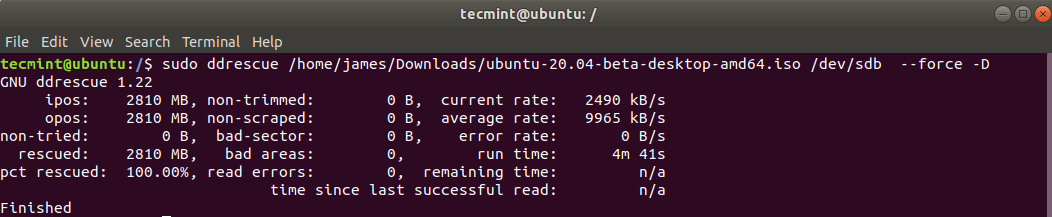
sudo ddrescue ubuntu-20.04-beta-desktop-amd64.iso /dev/sdb --force -D
El proceso tarda unos minutos y su unidad USB de arranque estará lista en poco tiempo.
Creación de un disco de inicio USB de Ubuntu usando el comando dd
Otra herramienta de línea de comandos sencilla y fácil de usar que puedes utilizar para crear un disco de inicio es el comando dd. Para utilizar la herramienta, conecte su unidad USB e identifique el volumen del dispositivo usando el comando lsblk.
A continuación, desmonte la unidad USB usando el siguiente comando:
sudo umount /dev/sdb
Una vez que la unidad USB esté desmontada, ejecute el siguiente comando:
sudo dd if=ubuntu-20.04-beta-desktop-amd64.iso of=/dev/sdb bs=4M
Donde Ubuntu-20.04-beta-desktop-amd64.iso es el archivo ISO y bs=4M es un argumento opcional para ayudar a acelerar el proceso de creación de la unidad de arranque.

Ahora puede expulsar su unidad Live USB y conectarla a cualquier PC y probar o instalar Ubuntu.
Esto nos lleva al final de este tema. Esperamos que esta guía te haya resultado útil y que ahora puedas crear cómodamente un disco de inicio USB de arranque utilizando todos los métodos aquí explicados.