15 consejos sobre cómo utilizar el comando 'Curl' en Linux
A mediados de la década de 1990, cuando Internet aún estaba en su infancia, un programador sueco llamado Daniel Stenberg inició un proyecto que eventualmente creció hasta convertirse en lo que hoy conocemos como curl.
Inicialmente, su objetivo era desarrollar un bot que descargara periódicamente los tipos de cambio de una página web y proporcionara equivalentes de coronas suecas en dólares estadounidenses a los usuarios de IRC.
En pocas palabras, el proyecto prosperó, agregando varios protocolos y características a lo largo del camino, y el resto es historia. ¡Ahora profundicemos y aprendamos cómo usar curl para transferir datos y más en Linux!
Hemos elaborado la siguiente lista de 15 comandos curl para usted.
1. Ver la versión de curl
Las opciones -V o --version no solo devolverán la versión, sino también los protocolos y funciones admitidos en su versión actual.
curl --version
curl 7.47.0 (x86_64-pc-linux-gnu) libcurl/7.47.0 GnuTLS/3.4.10 zlib/1.2.8 libidn/1.32 librtmp/2.3
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtmp rtsp smb smbs smtp smtps telnet tftp
Features: AsynchDNS IDN IPv6 Largefile GSS-API Kerberos SPNEGO NTLM NTLM_WB SSL libz TLS-SRP UnixSockets
2. Descargar un archivo
Si desea descargar un archivo, puede utilizar curl con las opciones -O o -o. El primero guardará el archivo en el directorio de trabajo actual con el mismo nombre que en la ubicación remota, mientras que el segundo le permite especificar un nombre de archivo y/o ubicación diferente.
curl -O http://yourdomain.com/yourfile.tar.gz # Save as yourfile.tar.gz
curl -o newfile.tar.gz http://yourdomain.com/yourfile.tar.gz # Save as newfile.tar.gz
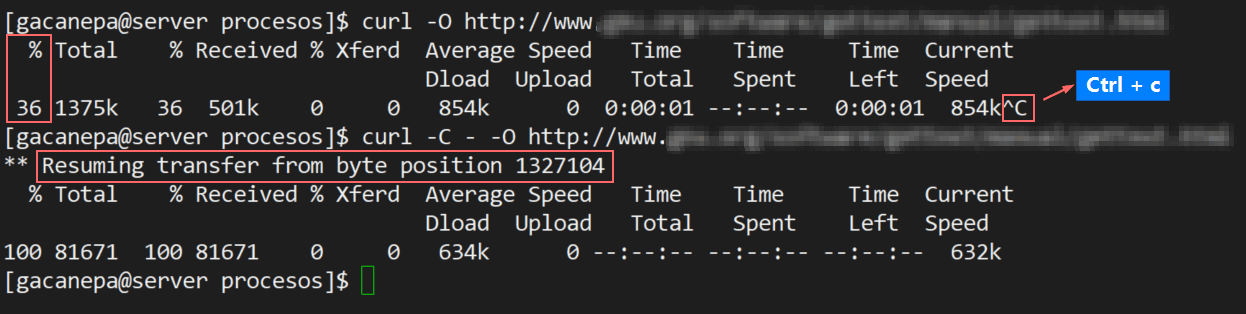
3. Reanudar una descarga interrumpida
Si una descarga se interrumpió por algún motivo (por ejemplo, usando Ctrl + c), puedes reanudarla muy fácilmente. El uso de -C – (guión C, guión espacial) le dice a curl que reanude la descarga comenzando donde la dejó.
curl -C - -O http://yourdomain.com/yourfile.tar.gz
4. Descargar varios archivos
Con el siguiente comando descargarás info.html y about.html de http://yoursite.com y http:/ /mysite.com, respectivamente, de una sola vez.
curl -O http://yoursite.com/info.html -O http://mysite.com/about.html
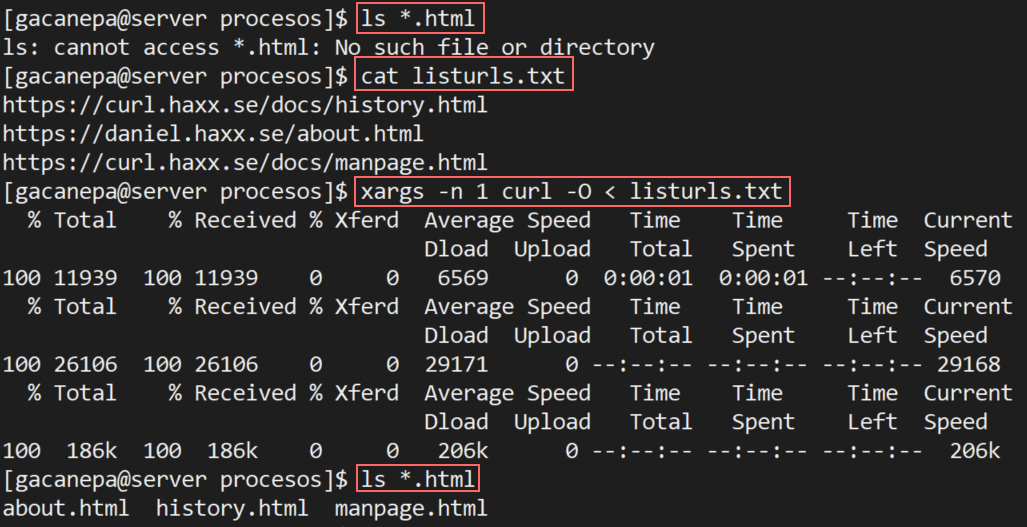
5. Descargar URL desde un archivo
Si combina curl con xargs, puede descargar archivos de una lista de URL en un archivo.
xargs -n 1 curl -O < listurls.txt
6. Utilice un Proxy con o sin autenticación
Si está detrás de un servidor proxy escuchando en el puerto 8080 en proxy.sudominio.com, hágalo.
curl -x proxy.yourdomain.com:8080 -U user:password -O http://yourdomain.com/yourfile.tar.gz
donde puede omitir -U usuario:contraseña si su proxy no requiere autenticación.
7. Consultar encabezados HTTP
Los encabezados HTTP permiten que el servidor web remoto envíe información adicional sobre sí mismo junto con la solicitud real. Esto proporciona al cliente detalles sobre cómo se está manejando la solicitud.
Para consultar los encabezados HTTP de un sitio web, haga:
curl -I linux-console.net

Esta información también está disponible en las herramientas de desarrollo de su navegador.
8. Realice una solicitud POST con parámetros
El siguiente comando enviará los parámetros firstName y lastName, junto con sus valores correspondientes, a https://tudominio.com/info.php .
curl --data "firstName=John&lastName=Doe" https://yourdomain.com/info.php
Puede utilizar este consejo para simular el comportamiento de un formulario HTML normal.
9. Descargar archivos desde un servidor FTP con o sin autenticación
Si un servidor FTP remoto espera conexiones en ftp://yourftpserver, el siguiente comando descargará yourfile.tar.gz en el directorio de trabajo actual.
curl -u username:password -O ftp://yourftpserver/yourfile.tar.gz
donde puede omitir -u nombre de usuario:contraseña si el servidor FTP permite inicios de sesión anónimos.
10. Cargar archivos a un servidor FTP con o sin autenticación
Para cargar un archivo local llamado mylocalfile.tar.gz a ftp://yourftpserver usando curl, haga lo siguiente:
curl -u username:password -T mylocalfile.tar.gz ftp://yourftpserver
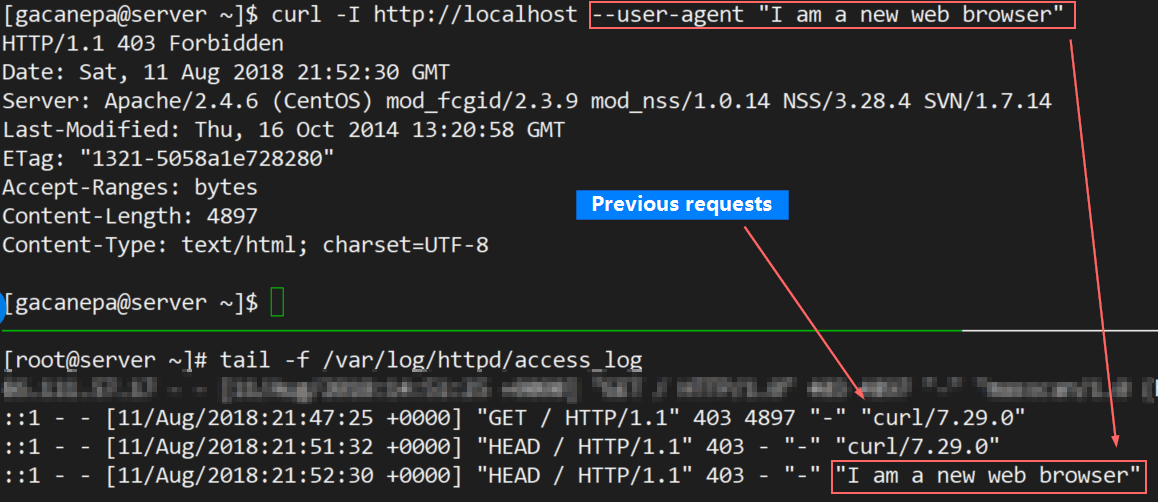
11. Especifique el agente de usuario
El agente de usuario es parte de la información que se envía junto con una solicitud HTTP. Esto indica qué navegador utilizó el cliente para realizar la solicitud. Veamos qué usa nuestra versión actual de curl de forma predeterminada y cambiémoslo más tarde a "Soy un nuevo navegador web":
curl -I http://localhost --user-agent "I am a new web browser"
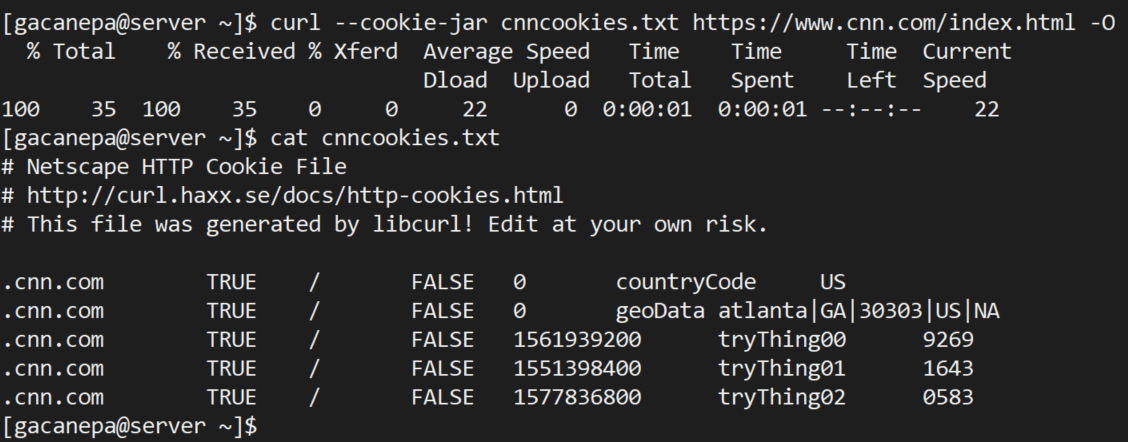
12. Almacenar cookies del sitio web
¿Quiere ver qué cookies se descargan en su computadora cuando navega en https://www.cnn.com? Utilice el siguiente comando para guardarlos en cnncookies.txt. Luego puede usar el comando cat para ver el archivo.
curl --cookie-jar cnncookies.txt https://www.cnn.com/index.html -O
13. Enviar cookies del sitio web
Puede utilizar las cookies recuperadas en el último consejo en solicitudes posteriores al mismo sitio.
curl --cookie cnncookies.txt https://www.cnn.com
14. Modificar la resolución del nombre
Si es desarrollador web y desea probar una versión local de tudominio.com antes de publicarla, puede hacer que curl resuelva http://www.tudominio.com a tu localhost así:
curl --resolve www.yourdomain.com:80:localhost http://www.yourdomain.com/
Por lo tanto, la consulta a http://www.tudominio.com le indicará a curl que solicite el sitio desde localhost en lugar de usar DNS o el archivo /etc/hosts.
15. Limitar la tasa de descarga
Para evitar que curl consuma su ancho de banda, puede limitar la velocidad de descarga a 100 KB/s de la siguiente manera.
curl --limit-rate 100K http://yourdomain.com/yourfile.tar.gz -O
Resumen
En este artículo hemos compartido una breve historia de los orígenes del curl y hemos explicado cómo utilizarlo a través de 15 ejemplos prácticos.
¿Conoce otros comandos curl que nos hayamos perdido en este artículo? ¡No dudes en compartirlos con nuestra comunidad en los comentarios! Además, si tiene preguntas no dude en hacérnoslo saber. ¡Esperamos con interés escuchar de usted!