Cómo buscar DuckDuckGo desde la terminal de Linux
Al igual que Googler (Google Site Search desde la línea de comandos), ddgr es una utilidad de línea de comandos que se puede utilizar para buscar palabras clave mediante el motor de búsqueda DuckDuckGo y un comando. navegador de línea en el indicador de su terminal.
Antes de instalar el motor de búsqueda de línea de comandos ddgr en Linux, primero asegúrese de que la biblioteca de solicitudes Python 3.4 y Python necesaria para manejar solicitudes HTTPS esté instalada en su sistema, emitiendo los siguientes comandos.
------------------ On CentOS, RHEL & Fedora ------------------
yum install epel-release
yum install python34 python34-requests
------------------ On Debian & Ubuntu ------------------
apt install python3 python3-requests
Para abrir búsquedas ddgr, necesita instalar un navegador de línea de comandos, como elinks, links, lynx, w3m . o www-browser, en su sistema.
Lea también: 8 herramientas de línea de comandos para navegar por sitios web
En esta guía configuraremos el motor de búsqueda ddgr para abrir enlaces a través del navegador basado en texto lynx.
yum insall lynx [On CentOS, RHEL & Fedora]
apt-get install lynx [On Debian & Ubuntu]
A continuación, configure la variable de entorno BROWSER en todo el sistema para que apunte al navegador lynx emitiendo los siguientes comandos con privilegios de root.
export BROWSER=lynx
echo “export BROWSER=lynx” >> /etc/profile
Para instalar la utilidad de línea de comandos del motor de búsqueda DuckDuckGo a través de las versiones oficiales del paquete binario ddgr github, ejecute los siguientes comandos específicos para su propia distribución de Linux.
------------------ On CentOS, RHEL & Fedora ------------------
yum install https://github.com/jarun/ddgr/releases/download/v1.1/ddgr-1.1-1.el7.3.centos.x86_64.rpm
------------------ On Ubuntu 16.04 ------------------
wget https://github.com/jarun/ddgr/releases/download/v1.1/ddgr_1.1-1_ubuntu16.04.amd64.deb
dpkg -i ddgr_1.1-1_ubuntu16.04.amd64.deb
------------------ On Ubuntu 17.10 ------------------
wget https://github.com/jarun/ddgr/releases/download/v1.1/ddgr_1.1-1_ubuntu17.10.amd64.deb
dpkg -i ddgr_1.1-1_ubuntu17.10.amd64.deb
------------------ On Debian 9 ------------------
wget https://github.com/jarun/ddgr/releases/download/v1.1/ddgr_1.1-1_debian9.amd64.deb
dpkg -i ddgr_1.1-1_debian9.amd64.deb
También puede instalar ddgr en Ubuntu utilizando un repositorio PPA, mantenido por el desarrollador del proyecto ddgr.
sudo add-apt-repository ppa:twodopeshaggy/jarun
sudo apt-get update
sudo apt-get install ddgr
Cómo buscar DuckDuckGo desde la terminal usando ddgr
Finalmente, para buscar una palabra clave específica en el motor de búsqueda ddgr, ejecute el comando como se muestra en el siguiente ejemplo.
ddgr tecmint
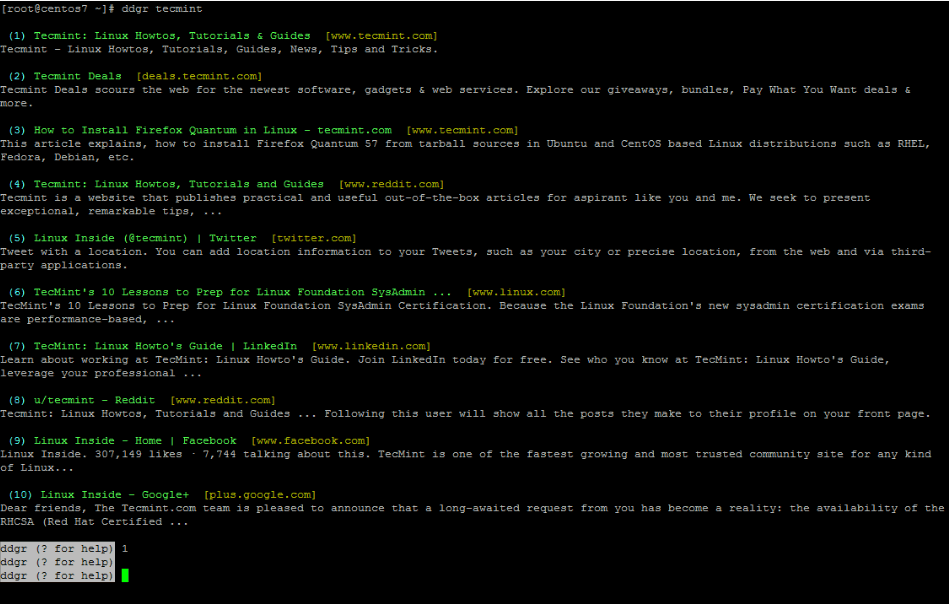
Para abrir automáticamente un resultado de búsqueda específico mostrado en el navegador de texto lynx, presione la tecla numérica correspondiente y espere a que se cargue la página web. A veces es necesario escribir “a” en el navegador lynx para aceptar siempre las cookies del sitio web y cargar el sitio web.
¡Eso es todo! Para obtener más información sobre la utilidad del motor de búsqueda de línea de comandos DuckDuckGo, visite la página oficial de github de ddgr.