Cómo salir de un archivo en Vi/Vim Editor en Linux
En este artículo, aprenderemos cómo salir del editor de texto Vi/Vim (después denominado Vim) usando comandos simples. En un artículo anterior, explicamos un consejo sencillo sobre cómo guardar un archivo en Vi o Vim después de realizar cambios en un archivo.
Antes de continuar, si es nuevo en Vim, le recomendamos leer estas 10 razones por las que debería seguir usando el editor de texto Vi/Vim en Linux.
Para abrir o crear un nuevo archivo usando Vi/Vim, simplemente escriba los siguientes comandos, luego presione i para cambiar al modo de inserción (insertar texto):
vim file.txt
OR
vi file.txt

Después de realizar cambios en un archivo, presione [Esc] para cambiar al modo de comando y presione :w y presione [Enter] para guardar un archivo.

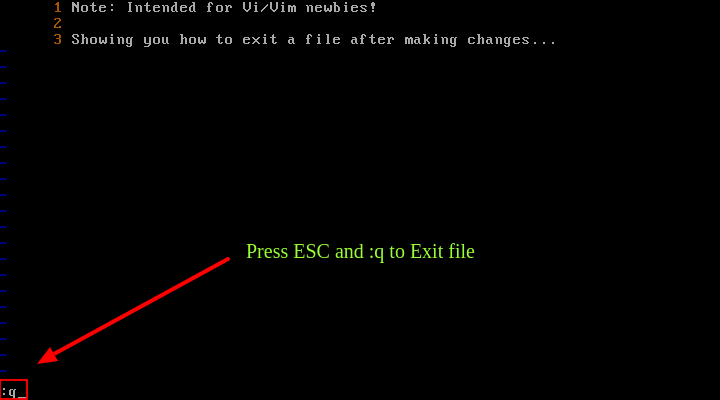
Para salir de Vi/Vim, use el comando :q y presione [Enter].
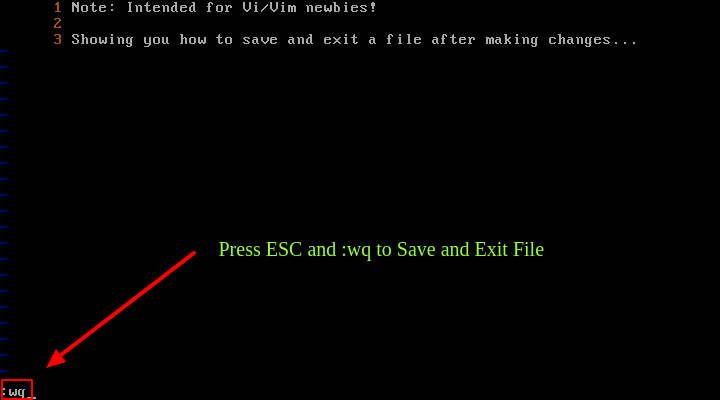
Para guardar un archivo y salir de Vi/Vim simultáneamente, use el comando :wq y presione el comando [Enter] o :x.
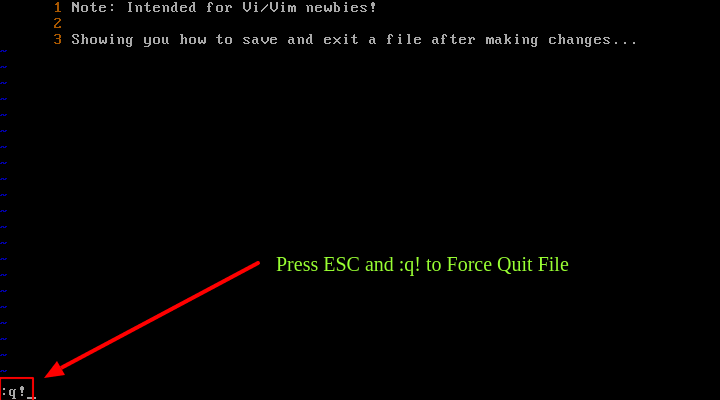
Si realiza cambios en un archivo pero intenta desactivar Vi/Vim usando las teclas ESC y q, recibirá un error como se muestra en la siguiente captura de pantalla.

Para forzar esta acción, utilice ESC y :q!.
Además, puede utilizar métodos abreviados. Presione la tecla [Esc] y escriba Shift + Z Z para guardar y salir o escriba Shift+ Z Q para salir sin guardar los cambios realizados en el archivo. .
Habiendo aprendido los comandos anteriores, ahora puede proceder a aprender los comandos avanzados de Vim desde los enlaces que se proporcionan a continuación:
- Aprenda consejos y trucos útiles del editor 'Vi/Vim' para mejorar sus habilidades
- 8 interesantes consejos y trucos del editor 'Vi/Vim' para todo administrador de Linux
En este artículo, aprendimos cómo salir del editor de texto Vim usando comandos simples. ¿Tiene alguna pregunta que hacer o alguna idea que compartir? Por favor, utilice el formulario de comentarios a continuación.