Cómo encontrar la diferencia entre dos directorios usando herramientas Diff y Meld
En un artículo anterior, revisamos las 9 mejores herramientas de comparación y diferencia de archivos (Diff) para Linux y en este artículo describiremos cómo encontrar la diferencia entre dos directorios en Linux.
Normalmente, para comparar dos archivos en Linux, utilizamos diff, una herramienta de línea de comandos de Unix simple y original que muestra la diferencia entre dos archivos de computadora; compara archivos línea por línea y es fácil de usar, viene preinstalado en la mayoría, si no en todas, las distribuciones de Linux.
La pregunta es ¿cómo obtenemos la diferencia entre dos directorios en Linux? Aquí queremos saber qué archivos/subdirectorios son comunes en los dos directorios, aquellos que están presentes en un directorio pero no en el otro.
La sintaxis convencional para ejecutar diff es la siguiente:
diff [OPTION]… FILES
diff options dir1 dir2
De forma predeterminada, su salida está ordenada alfabéticamente por nombre de archivo/subdirectorio, como se muestra en la siguiente captura de pantalla. En este comando, el modificador -q le indica a diff que informe solo cuando los archivos difieren.
diff -q directory-1/ directory-2/
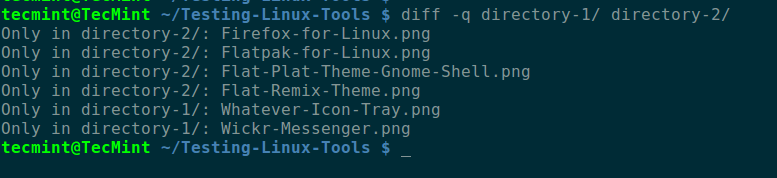
Nuevamente, diff no va a los subdirectorios, pero podemos usar el modificador -r para leer los subdirectorios también de esta manera.
diff -qr directory-1/ directory-2/
Uso de la herramienta Meld Visual Diff y Merge
Hay una opción gráfica interesante llamada meld (una herramienta visual de diferenciación y combinación para el escritorio GNOME) para aquellos que disfrutan usando el mouse, pueden instalarla de la siguiente manera.
sudo apt install meld [On Debian, Ubuntu and Mint]
sudo yum install meld [On RHEL/CentOS/Fedora and Rocky/AlmaLinux]
sudo emerge -a sys-apps/meld [On Gentoo Linux]
sudo apk add meld [On Alpine Linux]
sudo pacman -S meld [On Arch Linux]
sudo zypper install meld [On OpenSUSE]
sudo brew install meld [On macOS]
Una vez que lo hayas instalado, busca “meld” en el Ubuntu Dash o en el menú de Linux Mint, en Descripción general de actividades . en el escritorio Fedora o CentOS y ejecútelo.
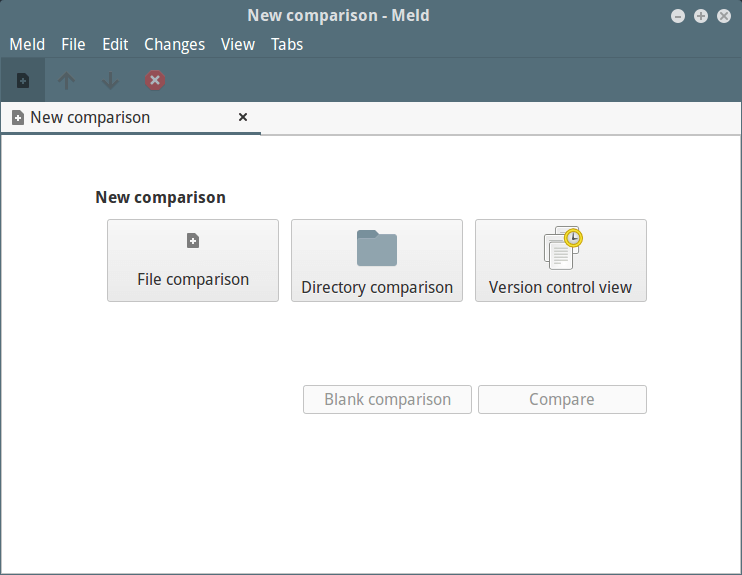
Verá la interfaz Meld a continuación, donde puede elegir la comparación de archivos o directorios, así como una vista de control de versiones. Haga clic en comparación de directorios y pase a la siguiente interfaz.
Seleccione los directorios que desea comparar; tenga en cuenta que puede agregar un tercer directorio marcando la opción “Comparación de tres vías”.
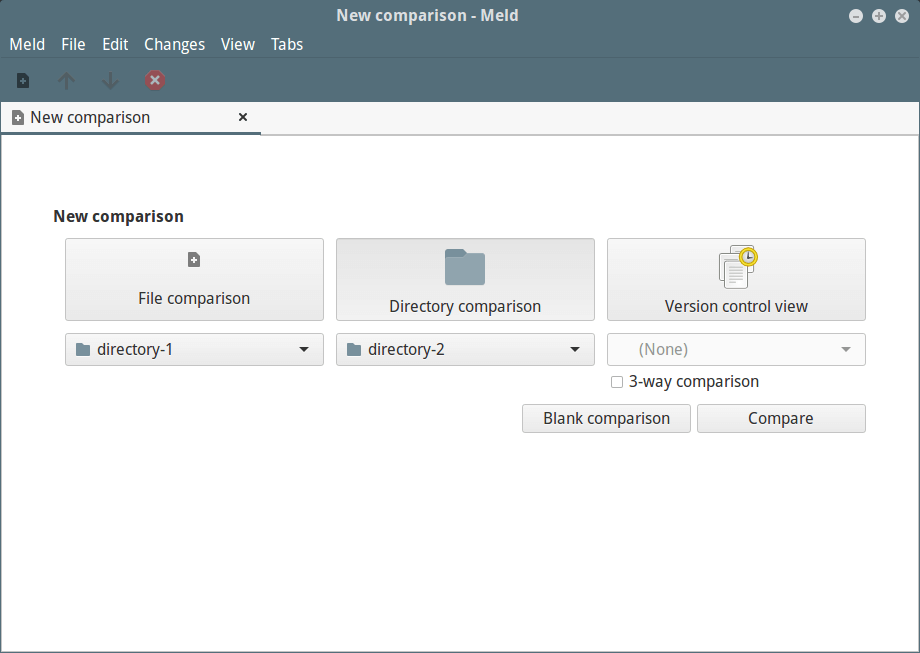
Una vez que haya seleccionado los directorios, haga clic en “Comparar”.

En este artículo, describimos cómo encontrar la diferencia entre dos directorios en Linux. Si conoce alguna otra línea de comando o interfaz gráfica de usuario, no olvide compartir sus opiniones sobre este artículo a través de la sección de comentarios a continuación.