Cómo convertir de RPM a DEB y de DEB a RPM usando Alien
Como estoy seguro ya sabes, hay muchas maneras de instalar software en Linux: usando el sistema de administración de paquetes proporcionado por tu distribución (aptitude, yum o zypper, por nombrar algunos ejemplos), compilando desde el código fuente (aunque de alguna manera raro hoy en día, era el único método disponible durante los primeros días de Linux), o utilizar una herramienta de bajo nivel como dpkg o rpm con .deb< y .rpm paquetes precompilados independientes, respectivamente.

En este artículo le presentaremos alien, una herramienta que convierte entre diferentes formatos de paquetes de Linux, desde .rpm a .deb (y viceversa). viceversa) siendo el uso más común.
Esta herramienta, incluso cuando su autor ya no la mantiene y afirma en su sitio web que alien probablemente siempre permanecerá en estado experimental, puede resultar útil si necesita un determinado tipo de paquete pero solo puede encontrar ese programa en otro formato de paquete.
Por ejemplo, alien me salvó el día una vez cuando estaba buscando un controlador .deb para una impresora de inyección de tinta y no pude encontrar ninguno: el El fabricante sólo proporcionó un paquete .rpm. Instalé alien, convertí el paquete y en poco tiempo pude usar mi impresora sin problemas.
Dicho esto, debemos aclarar que esta utilidad no debe usarse para reemplazar bibliotecas y archivos importantes del sistema, ya que están configurados de manera diferente según las distribuciones. Utilice alien sólo como último recurso si los métodos de instalación sugeridos al principio de este artículo están fuera de discusión para el programa requerido.
Por último, pero no menos importante, debemos tener en cuenta que aunque usaremos CentOS y Debian en este artículo, también se sabe que alien funciona en Slackware. e incluso en Solaris, además de las dos primeras distribuciones y sus respectivas familias.
Paso 1: Instalación de Alien y Dependencias
Para instalar alien en CentOS/RHEL 7, deberá habilitar EPEL y Nux Repositorios Dextop (sí, es Dextop, no de escritorio), en ese orden:
yum install epel-release
rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
La última versión del paquete que habilita este repositorio es actualmente la 0.5 (publicada el 10 de agosto de 2015). Debe consultar http://li.nux.ro/download/nux/dextop/el7/x86_64/ para ver si hay una versión más nueva antes de continuar:
rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
entonces hazlo,
yum update && yum install alien
En Fedora, sólo necesitarás ejecutar el último comando.
En Debian y derivados, simplemente haz:
aptitude install alien
Paso 2: Conversión del paquete .deb a .rpm
Para esta prueba hemos elegido dateutils, que proporciona un conjunto de utilidades de fecha y hora para manejar grandes cantidades de datos financieros. Descargaremos el paquete .deb a nuestra caja CentOS 7, lo convertiremos a .rpm y lo instalaremos:
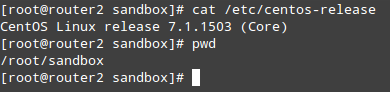
cat /etc/centos-release
wget http://ftp.us.debian.org/debian/pool/main/d/dateutils/dateutils_0.3.1-1.1_amd64.deb
alien --to-rpm --scripts dateutils_0.3.1-1.1_amd64.deb

Importante: (Tenga en cuenta cómo, de forma predeterminada, alien aumenta el número de versión menor del paquete de destino. Si desea anular este comportamiento, agregue el – mantener versión).
Si intentamos instalar el paquete de inmediato, nos encontraremos con un pequeño problema:
rpm -Uvh dateutils-0.3.1-2.1.x86_64.rpm

Para resolver este problema, habilitaremos el repositorio epel-testing e instalaremos la utilidad rpmrebuild para editar la configuración del paquete que se va a reconstruir:
yum --enablerepo=epel-testing install rpmrebuild
Entonces corre,
rpmrebuild -pe dateutils-0.3.1-2.1.x86_64.rpm
Lo que abrirá su editor de texto predeterminado. Vaya a la sección %files y elimine las líneas que hacen referencia a los directorios mencionados en el mensaje de error, luego guarde el archivo y salga:
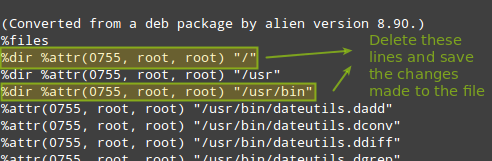
Cuando salga del archivo, se le pedirá que continúe con la reconstrucción. Si elige Y, el archivo se reconstruirá en el directorio especificado (diferente al directorio de trabajo actual):
rpmrebuild –pe dateutils-0.3.1-2.1.x86_64.rpm

Ahora puedes proceder a instalar el paquete y verificar como de costumbre:
rpm -Uvh /root/rpmbuild/RPMS/x86_64/dateutils-0.3.1-2.1.x86_64.rpm
rpm -qa | grep dateutils

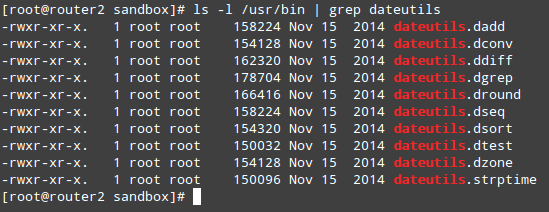
Finalmente, puede enumerar las herramientas individuales que se incluyeron con dateutils y, alternativamente, consultar sus respectivas páginas de manual:
ls -l /usr/bin | grep dateutils
Paso 3: Conversión del paquete .rpm a .deb
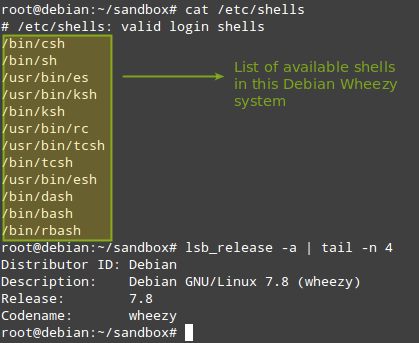
En esta sección ilustraremos cómo convertir de .rpm a .deb. En una caja Debian Wheezy de 32 bits, descarguemos el paquete .rpm para el shell zsh del sistema operativo CentOS 6. fuerte> repositorio. Tenga en cuenta que este shell no está disponible de forma predeterminada en Debian y derivados.
cat /etc/shells
lsb_release -a | tail -n 4
wget http://mirror.centos.org/centos/6/os/i386/Packages/zsh-4.3.11-4.el6.centos.i686.rpm
alien --to-deb --scripts zsh-4.3.11-4.el6.centos.i686.rpm
Puede ignorar con seguridad los mensajes sobre la falta de una firma:

Después de unos momentos, el archivo .deb debería haberse generado y estar listo para instalar:
dpkg -i zsh_4.3.11-5_i386.deb

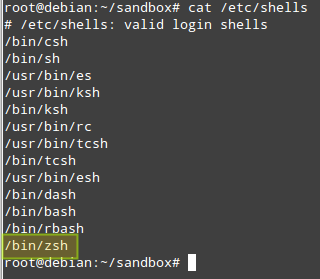
Después de la instalación, puede verificar que zsh se agregue a la lista de shells válidos:
cat /etc/shells
Resumen
En este artículo hemos explicado cómo convertir de .rpm a .deb y viceversa para instalar paquetes como último recurso cuando dichos programas no están disponibles en los repositorios o como código fuente distribuible. Querrá marcar este artículo como favorito porque todos necesitaremos extraterrestres en un momento u otro.
No dude en compartir sus opiniones sobre este artículo utilizando el siguiente formulario.