30 cosas que hacer después de una instalación mínima de RHEL/CentOS 7
CentOS es una distribución de Linux estándar de la industria que es un derivado de RedHat Enterprise Linux. Puede comenzar a utilizar el sistema operativo tan pronto como lo instale, pero para aprovechar al máximo su sistema necesita realizar algunas actualizaciones, instalar algunos paquetes y configurar ciertos servicios y aplicaciones.
Este artículo tiene como objetivo “30 cosas que hacer después de instalar RHEL/CentOS 7”. La publicación está escrita teniendo en cuenta que ha instalado la instalación mínima de RHEL/CentOS, que es la preferida en entornos empresariales y de producción; de lo contrario, puede seguir la guía a continuación que le mostrará las instalaciones mínimas de ambos.
- Instalación de CentOS 7 Mínimo
- Instalación de RHEL 7 mínimo
La siguiente es la lista de cosas importantes que hemos cubierto en esta guía según los requisitos estándar de la industria. Esperamos que estas cosas sean de gran ayuda para configurar su servidor.
1. Regístrese y habilite la suscripción a Red Hat
Después de una instalación mínima de RHEL 7, es hora de registrar y habilitar su sistema en los repositorios de Red Hat Subscription y realizar una actualización completa del sistema. Esto es válido sólo si tiene una suscripción RedHat válida. Debe registrarlo para habilitar los repositorios oficiales de RedHat System y actualizar el sistema operativo de vez en cuando.
Ya hemos cubierto instrucciones detalladas sobre cómo registrarse y activar la suscripción a RedHat en la siguiente guía.
- Registre y habilite los repositorios de suscripción de Red Hat en RHEL 7
Nota: este paso es solo para RedHat Enterprise Linux que tiene una suscripción válida. Si está ejecutando un servidor CentOS, continúe inmediatamente con los pasos siguientes.
2. Configurar la red con dirección IP estática
Lo primero que debe hacer es configurar la dirección IP estática, la ruta y el DNS en su servidor CentOS. Usaremos el comando ip para reemplazar el comando ifconfig. Sin embargo, el comando ifconfig todavía está disponible para la mayoría de las distribuciones de Linux y se puede instalar desde el repositorio predeterminado.
yum install net-tools [Provides ifconfig utility]

Pero como dije, usaremos el comando ip para configurar la dirección IP estática. Por lo tanto, asegúrese de verificar primero la dirección IP actual.
ip addr show

Ahora abra y edite el archivo /etc/sysconfig/network-scripts/ifcfg-enp0s3 usando el editor que elija. Aquí, estoy usando el editor Vi y me aseguro de que debes ser usuario root para realizar cambios...
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
Ahora editaremos cuatro campos en el archivo. Tenga en cuenta los cuatro campos siguientes y deje todo lo demás intacto. También deje las comillas dobles como están e ingrese sus datos en el medio.
IPADDR = “[Enter your static IP here]”
GATEWAY = “[Enter your Default Gateway]”
DNS1 = “[Your Domain Name System 1]”
DNS2 = “[Your Domain Name System 2]”
Después de realizar los cambios 'ifcfg-enp0s3', se parece a la imagen a continuación. Tenga en cuenta que su IP, GATEWAY y DNS variarán; confírmelo con su ISP. Guardar y Salir.

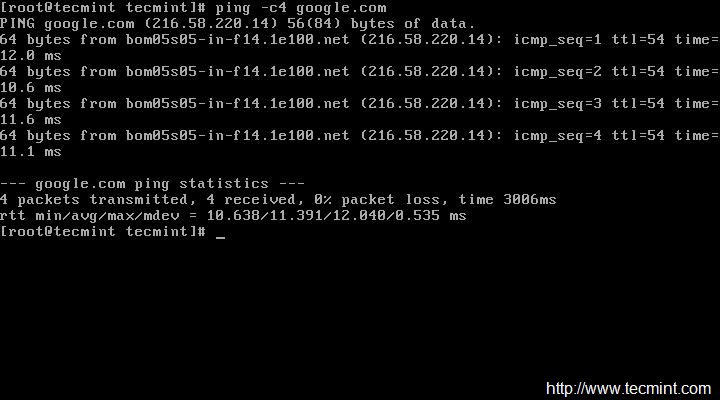
Reinicie la red de servicio y verifique que la IP que fue asignada sea correcta o no. Si todo está bien, Haga ping para ver el estado de la red...
service network restart
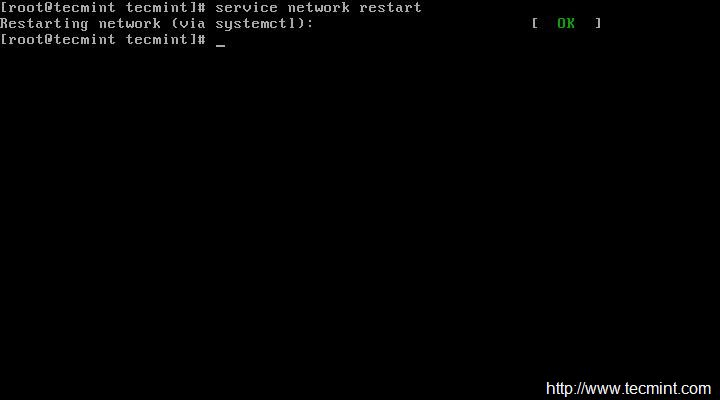
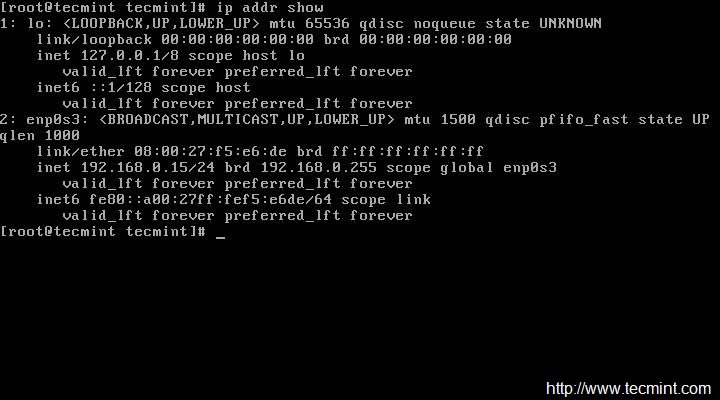
Después de reiniciar la red, asegúrese de verificar la dirección IP y el estado de la red...
ip addr show
ping -c4 google.com
3. Establecer el nombre de host del servidor
Lo siguiente que debe hacer es cambiar el HOSTNAME del servidor CentOS. Verifique el HOSTNAME asignado actualmente.
echo $HOSTNAME

Para configurar un nuevo NOMBRE DE HOST necesitamos editar '/etc/hostsname' y reemplazar el nombre de host anterior por el deseado.
vi /etc/hostname

Después de configurar el nombre de host, asegúrese de confirmarlo cerrando sesión y volviendo a iniciar sesión. Después de iniciar sesión, verifique el nuevo nombre de host.
echo $HOSTNAME
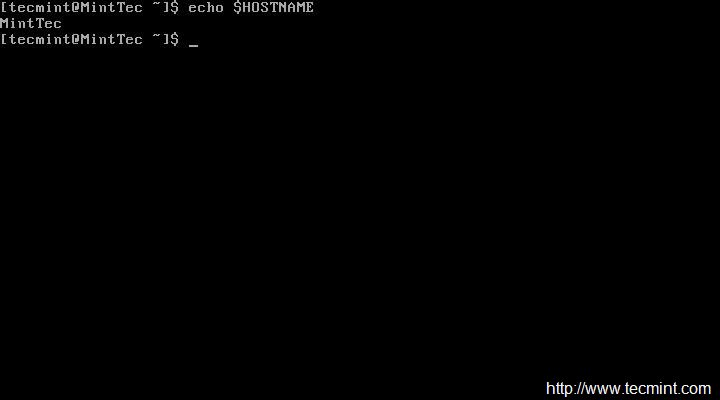
Alternativamente, puede usar el comando 'nombre de host' para ver su nombre de acceso actual.
hostname
4. Actualizar o actualizar la instalación mínima de CentOS
Esto no instalará ningún paquete nuevo más que actualizar e instalar la última versión de los paquetes instalados y las actualizaciones de seguridad. Además, Actualizar y Actualizar son bastante iguales excepto por el hecho de que Actualizar=Actualizar + habilita el procesamiento de obsoletos durante las actualizaciones.
yum update && yum upgrade
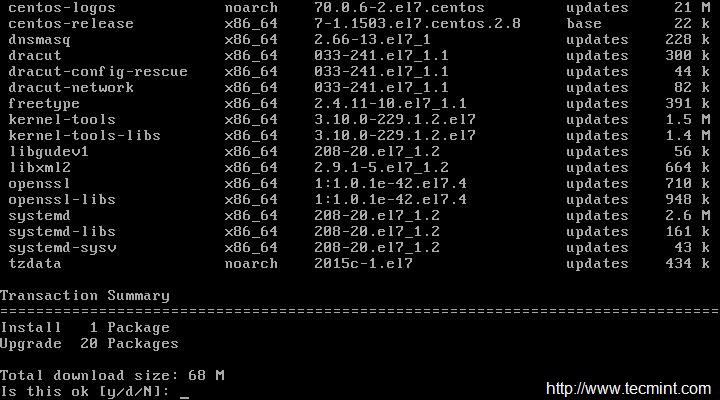
Importante: También puede ejecutar el siguiente comando que no solicitará la actualización de los paquetes y no necesita escribir 'y' para aceptando los cambios.
Sin embargo, siempre es una buena idea revisar los cambios que se producirán en el servidor, especialmente en producción. Por lo tanto, el uso del siguiente comando puede automatizar la actualización y la actualización, pero no se recomienda.
yum -y update && yum -y upgrade
5. Instale el navegador web de línea de comandos
En la mayoría de los casos, especialmente en el entorno de producción, normalmente instalamos CentOS como línea de comandos sin GUI; en esta situación debemos tener una herramienta de navegación de línea de comandos para verificar sitios web a través de la terminal. Para ello, instalaremos una herramienta muy famosa llamada 'enlaces'.
yum install links
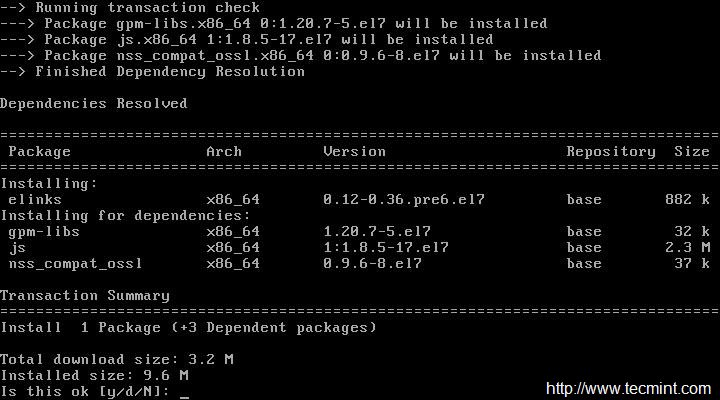
Para conocer el uso y ejemplos para navegar por sitios web con la herramienta de enlaces, lea nuestro artículo Navegación web con línea de comandos con la herramienta de enlaces
6. Instale el servidor HTTP Apache
No importa para qué utilizará el servidor, en la mayoría de los casos necesitará un servidor HTTP para ejecutar sitios web, multimedia, scripts del lado del cliente y muchas otras cosas.
yum install httpd

Si desea cambiar el puerto predeterminado (80) del servidor Apache HTTP a cualquier otro puerto. Debe editar el archivo de configuración '/etc/httpd/conf/httpd.conf' y buscar la línea que comienza normalmente así:
LISTEN 80
Cambie el número de puerto '80' a cualquier otro puerto (digamos 3221), guarde y salga.

Agregue el puerto que acaba de abrir para Apache a través del firewall y luego vuelva a cargar el firewall.
Permitir el servicio http a través del firewall (Permanente).
firewall-cmd --add-service=http
Permitir el puerto 3221 a través del firewall (Permanente).
firewall-cmd --permanent --add-port=3221/tcp
Vuelva a cargar el cortafuegos.
firewall-cmd --reload
Después de hacer todo lo anterior, ahora es el momento de reiniciar el servidor Apache HTTP, para que el nuevo número de puerto entre en vigor.
systemctl restart httpd.service
Ahora agregue el servicio Apache a todo el sistema para que se inicie automáticamente cuando se inicie el sistema.
systemctl start httpd.service
systemctl enable httpd.service
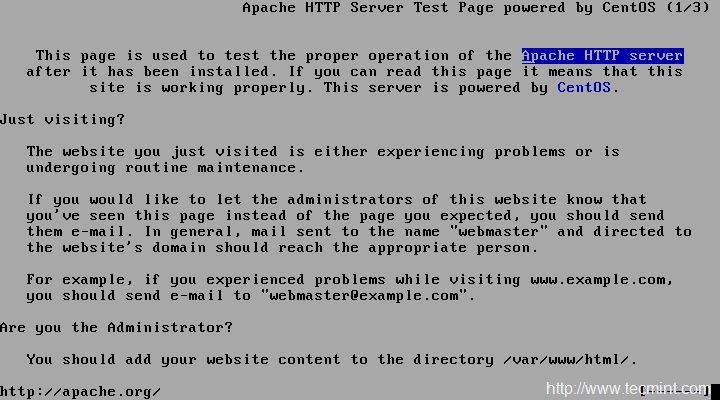
Ahora verifique el servidor HTTP Apache utilizando la herramienta de línea de comandos de enlaces como se muestra en la siguiente pantalla.
links 127.0.0.1